(Chinese) 《An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》论文翻译
《An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》论文翻译
· 7 min read

本篇文章是对论文An Empirical Evaluation of In-Memory Multi-Version Concurrency Control的原创翻译,转载请严格遵守CC BY-NC-SA协议。
作者 #
Yingjun Wu National University of Singapore yingjun@comp.nus.edu.sg
Joy Arulraj Carnegie Mellon University jarulraj@cs.cmu.edu
Jiexi Lin Carnegie Mellon University jiexil@cs.cmu.edu
Ran Xian Carnegie Mellon University rxian@cs.cmu.edu
Andrew Pavlo Carnegie Mellon University pavlo@cs.cmu.edu
摘要 #
多版本并发控制(Multi-version concurrency control,MVCC)目前是现代数据库管理系统(DBMS)中最热门的事务管理策略。尽管MVCC在1970年代晚期就已经被发明出来了,但是在过去的十年中,在几乎所有主要的关系型DBMS中都使用了它。在处理事务时,维护数据的多个版本可以在不牺牲串行性的同时提高并行性。但是在多核和内存的配置中扩展MVCC并非易事:当有大量线程并行运行时,同步带来的开销可能超过多版本带来的好处。
为了理解在现代的硬件配置下处理事务时MVCC如何执行,我们对MVCC的4个关键设计决策进行了大量研究:并发控制协议、版本存储、垃圾回收、和索引管理。我们在内存式DBMS中以最高水平实现了这些所有内容的变体,并通过OLTP负载对它们进行了评估。我们的分析确定了每种设计选择的基本瓶颈。
1. 引言 #
计算机体系结构的进步导致了多核内存式DBMS的兴起,它们使用了高效的事务管理机制以在不牺牲串行性的同时提高并行性。在最近十年的里,在DBMS开发中使用的最流行的策略是多版本并发控制(multi-version concurrency control,MVCC) 。MVCC的基本想法是,DBMS为数据库中的每个逻辑对象维护多个物理版本,让对同一个对象的操作能够并行执行。这些对象可以是任何粒度上的,但是几乎所有的MVCC DBMS都使用了元组(tuple),因为它在并行性和版本追踪(version tracking)的开销间提供了很好的平衡。多版本化可以让只读的事务访问元组的旧版本,而不会阻止读写事务在同事生成新的版本。这与单版本的系统不同,在单版本系统中,事务总是会在更新一个元组时时用新数据覆写它。
最近DBMS使用MVCC的这一趋势的有趣之处在于,MVCC策略并不是新技术。第一次提到MVCC似乎是在1979年的一篇论文中[38],它的第一个实现始于1981年的InterBase DBMS[22](现在作为Firebird开源)。如今,MVCC还用于一些部署最广泛的面向磁盘的DBMS中,包括Oracle(自1984年起[4]),Postgres(自1985年起[41])和MySQL的InnoDB引擎(自2001年起)。但是,尽管有很多与这些较早的系统同时代的系统使用了单版本策略(例如,IBM DB2、Sybase),但是几乎所有新的支持事务的DBMS都避开了单版本策略转而使用MVCC[37]。无论商业系统(例如,Microsoft Hekaton[16]、SAP HANA[40]、MemSQL[1]、NuoDB[3])还是学术系统(例如,HYRISE[21]、HyPer[36])都是如此。
尽管所有的这些新系统都使用了MVCC,但是MVCC并没有一个“标准”实现。在一些设计中选择了不同的权衡点(trade-off)和性能表现。直到现在,都没有在现代DBMS操作环境中的对MVCC的全面的评估。最近的大量的研究在1980年代[13],但是它在单核CPU上运行的面向磁盘的DBMS中使用了模拟的负载。古老的面向磁盘的DBMS的设计上的选择并不适用于运行在有更多CPU核数的机器上的内存式DBMS。因此,这项过去的研究并不能反映出最近的无闩(latch-free)[27]和串行[20]的并发控制与内存式存储[36]和混合负载[40]的趋势。
在本文中,我们对MVCC DBMS中关键的事务管理设计决策进行了研究:(1)并发控制协议(concurrency control protocol)(2)版本存储(version storage)(3)垃圾回收(garbage collection)(4)索引管理(index management)。对于每一个主题,我们都描述了内存式DBMS中的最先进的实现,并讨论了它们的做出的权衡。我们还重点介绍了阻止它们扩展以支持更多线程数和更复杂的负载的问题。作为调研的一部分,我们在内存式MVCC DBMS Peloton[5]中实现了所有的这些方法。这为我们提供了可以比较这些实现的统一的平台,且不受没实现的架构设计所影响。我们在40核的机器上部署了Peloton,并通过两个OLTP benchmark对其进行评估。我们的分析确定了对我们的实现造成压力的场景,并讨论了缓解它们的方式(如果可能的话)。
2. 背景 #
我们首先提供了MVCC的上层概念的总览。然后讨论了DBMS追踪事务与维护版本信息用的元数据。
2.1 MVCC总览 #
事务管理策略让终端用户能够通过多个程序访问数据库且让每个用户以为自己在一个单独的专用系统上执行[9]。它确保了DBMS的原子性和隔离性的保证。
对于现代数据库程序来说,多版本系统有一些优势。其中最重要的是,多版本系统比单版本系统能支持更高的并发。例如,MVCC DBMS允许在一个事务读一个对象的较旧的版本的同时另一个事务更新该对象。这一点十分重要,因为数据库执行只读查询的同时读写事务能够继续更新它。如果DBMS永远都不移除旧版本,那么系统就能够支持“时间旅行”操作,让应用程序能够像在过去的某个时间点一样查询数据库的快照[8]。
以上的好处让MVCC成为近些年DBMS的实现中最流行的选择。表1 提供了过去30年中MVCC的实现的总结。然而,在DBMS中实现多版本有很多种方式,每种方法都会产生不同的额外计算与存储开销。这些设计上的决策也高度互相依赖。因此,判断哪些设计决策比其它的好且为什么比其它的好并非易事。而在磁盘不再成为瓶颈的内存式DBMS中更是这样。
在接下来的章节中,我们将讨论这些设计决策实现上的问题和性能权衡点。接着我们在第7章对它们进行了全面的评估。我们注意到,本文中仅考虑了串行事务执行。尽管日志和恢复是DBMS架构中很重要方面,但是我们的研究中并没有包括它们,因为它们与单版本系统中的没什么不同,且内存式DBMS日志已经在别处被研究过了[39, 49]。
2.2 DBMS元数据 #
无论实现方式如何,MVCC DBMS都会维护用于事务和数据库元组的通用的元数据。
事务: 当事务$T$首次进入DBMS系统时,DBMS会为该事务分配一个唯一、单调递增的时间戳作为它的标识符($ T_{id} $)。并发控制协议使用这种标识符来标记事务访问的元组的版本。一些协议还用它作为事务串行的顺序。
元组: 如图1所示,每个“物理”版本在它的头部中都包括4个元数据字段,DBMS用它来协调并发事务的执行(下一章中讨论的一些并发控制协议包括了额外的字段)。txn-id字段被用作版本的写入锁。如果元组没被锁定写入,那么该元组的这一字段会被置零。大部分的DBMS都使用64位的txn-id,这样它可以通过一次compare-and-swap(CaS)指令原子性的更新该值。如果标识符为$ T_{id} $的事务$T$想要更新元组$A$,那么DBMS会检查$A$的txn-id字段是否为零。如果是,那么DBMS会通过一个CaS指令将txn-id置为$ T_{id} $[27, 44]。如果一个事务试图更新$A$,当这一txn-id既不是0也不等于该事务的$ T_{id} $时,该事务会被打断。接下来的两个元数据字段是begin-ts和end-ts,它们记录了表示元组版本生命周期的时间戳。这两个字段最初都会被置零。DBMS会在事务删除元组时把改元组的begin-ts置为INF。最后一个元数据字段是一个保存相邻(前一个或后一个)版本的地址的指针pointer(如果有的话)。

3. 并发控制协议 #
每个DBMS都有一个用来协调并发事务执行的并发控制协议 [11]。该协议确定了(1)在数据库运行时中,是否允许某个事务访问或修改一个特定的元组版本(2)是否允许某个事务提交它的修改。尽管这些协议的基本原理从1980年代就没改变过,但是在没有磁盘操作的多核和内存为主的配置下,它们的性能特征已经发生了巨大的变化[42]。因此,有些新兴的高性能的DBMS变体移除了锁(lock)/闩(latch)和中央的数据结构,并为字节可寻址存储(byte-addressable storage)进行了优化。
本章中,我们描述了MVCC DBMS的4中核心并发控制协议。我们仅考虑了使用元组级锁的协议,因为这足以确保串行化执行。我们忽略了范围查询,因为多版本没有为防止幻读带来任何好处[7]。已有的提供了串行事务处理的方法,(1)或者在索引上使用了额外的闩[35, 44],(2)或者在事务提交时使用了额外的校验步骤[27]。
3.1 时间戳排序(Timestamp Ordering)——MVTO #
1979年的MVTO算法被认为是最初的并发控制协议[38, 39]。该方法的核心在于使用事务的标识符($ T_{id} $)来预计算它们的串行顺序。除了章节2.2中描述的字段以外,其版本头中还包括最后一次读取了它的事务的标识符(read-ts)。当事务视图读取或更新一个被其它事务持有其写入锁的版本时,DBMS会打断该事务。
当事务$T$在逻辑元组$A$上调用了一个读操作时,DBMS会搜索一个能使该$ T_{id} $在其begin-ts和end-ts字段的范围间的物理版本。如图2a所示,如果版本$A_x$的写入锁没有被另一个活动的事务持有(即,txn-id的值为0或等于$ T_{id} $),那么$T$会被允许读取该版本,因为MVTO永远不会允许一个事务读取未提交的版本。一旦事务读取了$A_x$,如果$A_x$的read-ts字段的当前值小于$ T_{id} $,那么DBMS会将其置为$ T_{id} $。否则,该事务将读取一个较旧的版本,且不会更新该字段。

通过MVTO,事务总能更新元组的最新版本。如果(1)没有持有$B_x$的写入锁的活动的事务,且(2)$ T_{id} $的值比$B_x$的read-ts字段大,事务$T$会创建一个新版本$ B_{x+1} $。如果这些条件被满足,那么DBMS会创建一个新版本$ B_{x+1} $并将其txn-id置为$ T_{id} $。当$T$提交时,DBMS会分别将$ B_{x+1} $的begin-ts和end-ts字段置为$ T_{id} $和INF,并将$B_x$的end-ts字段置为$ T_{id} $。
3.2 乐观并发控制(Optimistic Concurrency Control)——MVOCC #
接下来的协议基于1981年提出的乐观并发控制策略(OCC)[26]。OCC背后的动机是,DBMS假设事务冲突的可能性不大,因此当事务读取或更新元组时没有必要获取元组上的锁。这减少了事务持有锁的总时间。为了使原始的OCC协议适应多版本,需要对它作出一些修改[27]。其中最重要的是,DBMS不会为事务维护一个私有的工作空间(workspace),因为元组的版本信息已经防止了事务读取或更新应对它们不可见的版本。
MVOCC协议将事务分为了3个阶段。当事务开始时,它处于读阶段(read phase) 。这是事务在数据库上调用读或更新操作的阶段。与MVTO相似,为了在元组$A$上执行读操作,DBMS首先会基于元组的begin-ts和end-ts字段搜索一个可见的版本$A_x$。如果版本$A_x$的写入锁没被获取,那么$T$会被允许更新该版本。在多版本配置下,如果事务更新了版本$B_x$,那么DBMS会创建版本$ B_{x+1} $并将其txn-id置为$ T_{id} $。
当事务告知DBMS它要提交时,事务会进入校验阶段(validation phase) 。首先,DBMS会为该事务分配另一个时间戳($ T_{commit} $)来确定该事务读取的元组的集合是否被一个已提交的事务更新了。如果该事务通过过了这些检查,那么它会进入写阶段(write phase) ,在这一阶段DBMS会安装(install)所有的新版本且将它们的begin-ts置为$ T_{commit} $并将end-ts置为INF。
事务只能更新元组的最新的版本。但是事务在其它事务创建新版本的提交前,它都不能读该新版本。读到过时版本的事务仅会在校验阶段发现它应该终止。
3.3 两阶段锁(Two-phase Locking)——MV2PL #
该协议使用了两阶段锁(2PL)的方法[11]来确保事务的串行性。每个事务在被允许读取或修改逻辑元组的当前版本前,需要获取适当的锁。在基于磁盘的DBMS中,锁会与元组分开存储,这样锁永远不会被换出(swap)到磁盘中。而在内存式DBMS中,分开存储时不必要的,因此使用MV2PL时,锁被嵌入在了元组的头部中。元组的写入锁 是txn-id字段。而对于读取锁 ,DBMS使用read-cnt字段对读取该元组的活动的事务计数。尽管不是必需的,DBMS还是将txn-id和read-cnt装入连续的64位字中,这样DBMS可以使用一个CaS指令来同时更新它们。
为了对元组$A$执行读操作,DBMS会通过将事务的$ T_{id} $和元组的begin-ts进行比较来搜索一个可见的版本。如果它找到了一个有效地版本,DBMS会在它的txn-id字段等于零时(这意味着没有其它的事务持有着它的写入锁)将该元组的read-cnt字段加一。类似地,当事务仅在版本$B_x$的read-cnt和txn-id都被置为零使才被允许更新它。当事务提交时,DBMS会为它分配一个唯一的时间戳$ T_{commit} $,其被用于更新由该事务创建的其它版本的begin-ts字段,并随后释放该事务所有的锁。
2PL协议间的关键区别在于它们如何处理死锁。之前的研究表明无等待(no-wait) 策略[9]是可伸缩性最好的防死锁技术[48]。使用这一策略,DBMS会在事务不能获取元组的锁时立刻打断它(与等待并看锁是否被释放相反)。因为事务永远不会等待,DBMS没必要使用一个后台线程来检测并打破死锁。
3.4 串行验证者(Serialization Certifier) #
在最后一个协议中,DBMS会维护一个串行图(serialization graph)来检测并移除当前事务形成的“危险结构”[12, 20, 45]。在较弱的隔离界别之上可以采用基于验证着的方法,这能提供更好的性能但是允许出现某些异常情况。
第一个提出验证者方法的是可串行快照隔离(serializable snapshot isolation,SSI)[12]。这种方法通过避免写倾斜的异常(write-skew anomly)来确保串行性以提供快照隔离。SSI使用事务的标识符来索索元组的可见版本。事务仅当元组的txn-id字段被置为零时才能更新其版本。为了确保串行性,当事务创建了一个元组的新版本同时该元组之前的版本被另一个事务读取时,DBMS会在其内部的图中追踪反依赖(anti-dependency) 边。DBMS会为每个事务维护一些标识(flag)以追踪反依赖边的入度和出度。当DBMS检测到两个事务间有两个连续的反依赖边时,它会打断其中一个事务。
串行安全网络(serial safety net,SSN)是一种新兴的基于验证着的协议[45]。不像仅适用于快照隔离的SSI,SSN能在强度至少与READ COMMITTED相同的任何隔离界别中工作。它还是用了更精确的异常检测机制,减少了被不必要打断的事务的数量。SSN将事务依赖信息编码为元数据字段,并通过计算一个能汇总在$T$之前提交但必须在T之后串行执行的“危险”事务的“低水位标记(low watermark)”来校验事务$T$的一致性[45]。SSn能够减少错误打断的数量,这使它更适用于只读或以读取为主的事务负载。
3.5 探讨 #
这些协议处理冲突的方式不同,因此在某些负载下,一些协议会比其它协议更好。MV2PL使用每个版本的读取锁来记录读取。因此,对一个元组版本执行读或写的事务会导致另一个试图对该版本做相同操作的事务终止。而MVTO使用了每个版本的read-ts字段来记录读取。MVOCC在处理读操作时不会更新元组版本头部的任何字段。这避免了线程间不必要的协调,且读取某一版本的事务不会导致其它更新相同版本的事务被打断。但是MVOCC要求DBMS检验事务的读集合以验证该事务读操作的正确性。这可能导致长期运行的只读事务长时间不会被执行(译注:原文为“starvation”)[24]。而验证者协议因不需要验证读取而减少了事务打断,但是它们的反依赖检查策略可能会带来额外的开销。
一些协议优化了上面的协议以改进它们在MVCC DBMS中的功效[10, 27]。一种方法让事务能够预先读取(speculatively) 其它事务创建的未提交的版本。而作为权衡,协议必须追踪事务的读依赖以确保可以串行排序。每个工作线程会维护一个依赖计数器(dependency counter) ,以计数该事务读取的未提交的数据对应的事务的个数。事务仅在它的依赖计数器为零时才被允许提交,因此,在事务提交时DBMS会遍历其以来列表并减小所有等待它完成的事务的计数器。类似地,另一种优化机制让事务能够预先更新(eagerly update) 被其它未提交的事务读取的版本。这一优化也需要DBMS维护中央数据结构以追踪事务间的依赖。一个事务仅当所有它依赖的事务已经提交后才能提交。
以上描述的两种优化都能减少某些负载下不必要的打断数量,但是它们都收级联终止(cascading abort)影响。此外,我们发现维护中央数据结构可能成为主要的性能瓶颈,这会让DBMS不能扩展到几十个核心的配置。
4. 版本存储 #
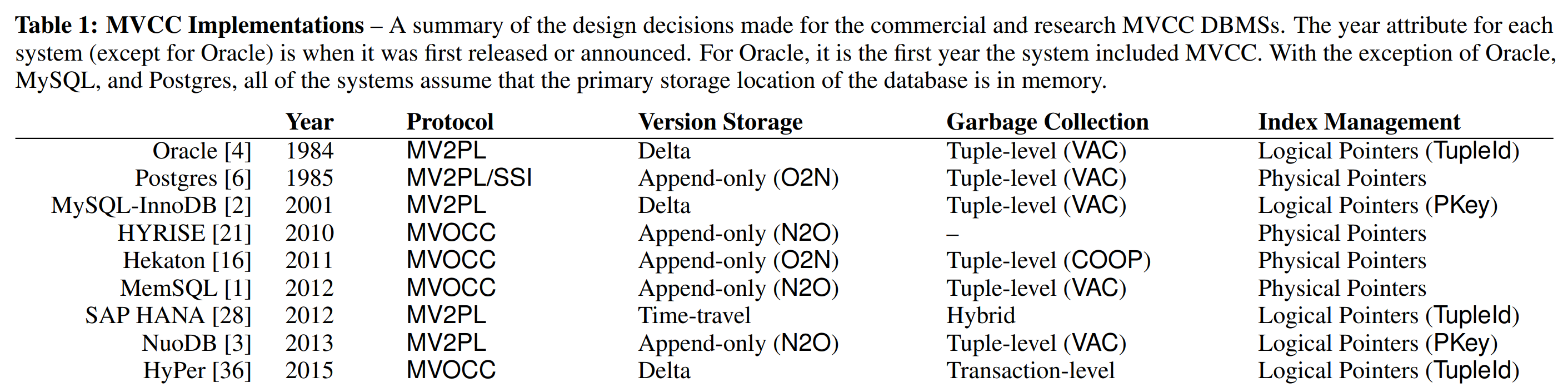
在MVCC下,当事务更新一个元组时DBMS总是会为该元组构造一个新的物理版本。DBMS的版本存储策略(version storage scheme) 决定了系统如何保存这些版本与每个版本包含什么信息。DBNS使用元组的pointer字段创建了一个被称为版本链(version chain) 的无闩链表。版本链让DBMS能够定位所需的对事务可见的元组版本。正如我们下面讨论的一样,链头(HEAD)既可能是最新版本也可能是最旧版本。
现在我们将更详细地描述这些策略。我们的讨论将聚焦于策略对UPDATE操作的权衡,因为这时DBMS处理版本控制之处。DBMS将新元组插入到表时不必更新其它的版本。同样,DBMS通过在当前版本的begin-ts字段设置一个标识来删除元组。在后续的章节中,我们将讨论这些存储策略对DBMS如何执行垃圾回收与DBMS如何在索引中维护指针的影响。
4.1 仅追加存储(Append-only Storage) #
在第一个策略中,表的所有元组版本被保存到相同的存储空间中。这种方法在Postgres与Hekaton、NuoDB、和MemSQL等内存式DBMS中使用。为了更新已有的元组,DBMS首先从表中为新版本请求一个空的槽(slot)。然后它会将当前版本的内容复制到新版本中。最后,它会修改应用到元组中新配的的版本槽上。
仅追加策略的关键决策在于DBMS如何对元组的版本链进行排序。因为不可能维护无闩双向链表,所以版本链仅指向一个方向。这一顺序对事务修改元组时DBMS更新索引的频率有影响。
从老到新(Oldest-to-Newest,O2N): 在这种顺序下,链头是元组现存的最老的版本(如图3a所示)。这一版本可能对任何活动的事务都不可见,但是DBMS还没有回收它。O2N的优势在于,在元组被修改时,DBMS不需要更新索引使其指向元组的新版本。但是DBMS在查询处理期间可能要遍历很长的版本链来找到最新版本。因为这一操作是pointer-chasing(译注:指遍历由指针链接在一起的数据结构,因为下一个元组总是不在缓存中,因此在遍历过程中会不断引起内存操作)的且这一操作会因读取了不需要的版本而污染CPU缓存,所以这一操作很慢。因此,通过O2N实现良好的性能高度依赖系统对旧版本剪枝的能力。
从新到老(Newest-to-Oldest,N2O): 这种顺序将元组最新的版本作为版本链的链头保存(如图3b所示)。因为大部分事务都访问元组的最新版本,所以DBMS不必遍历整个链。然而,其缺点是在于,每当元组被修改后链头都会变化。随后DBMS会更新该表的所有索引(索引的前项(primary)和后项(secondary)都要更新)以指向新版本。正如我们在章节6.1中讨论的那样,可以通过一个间接层来避免这一个问题,该层提供了一个将元组的最新版本映射到物理地址的位置。在这种配置下,索引指向元组的映射条目而不是它们的物理位置。这在有很多后项索引的表中表现良好,但是增加了额外的存储开销。
仅追加存储的另一个问题是,如何处理非内联(non-inline)属性(例如BLOB)。考虑一个有两个属性的表(一个是整型,一个是BLOB)。在仅追加策略下,当一个事务更新该表的一个元组时,DBMS会创建该BLOB属性的一份拷贝(即使事务么有修改它),且随后新版本会指向这份拷贝。因为这创建了冗余的拷贝,所以这一操作很浪费。为了避免这一个问题,一种优化是让相同元组的多个物理版本指向同一个非内联数据。DBMS维护该数据的引用计数来确保其值仅在它们不再被任意版本引用时才会被删除。
4.2 时间旅行存储(Time-Travel Storage) #
下一种存储策略与仅追加方法相似,除了该策略中旧版本被保存在单独的表中。DBMS在主表(main table)中为每个元组维护一个master版本,并在单独的时间旅行表(time-travel table)中维护同一个元组的多个版本。在一些DBMS中(如SQL Server),master版本时元组的当前版本。其他系统(如SAP HANA)将元组最旧的版本作为master版本保存,以提供快照隔离(snapshot isolation)[29]。这会增加GC时的额外维护开销,因为在DBMS剪掉当前的master版本时,需要将数据从时间旅行表拷贝回主表中。为了简单起见,我们仅考虑第一种时间旅行方法,即master版本总是在主表中的方法。
为了更新一个元组,DBMS首先会在时间旅行表中获取一个槽,然后将master版本拷贝到这个位置上。然后,它会修改保存在主表上的master版本。因为索引总是指向master版本,所以索引不会受版本链更新的影响。因此,这避免了每次事务更新一个元组时维护数据库索引的额外开销,且对于访问元组当前版本的查询来说非常理想。
这种策略与仅追加方法一样,也受非内联属性问题影响。我们之前描述的数据共享优化同样适用于此。
4.3 增量存储(Delta Storage) #
在最后一种策略中,DBMS在主表中维护元组的master版本 ,并在一个独立的增量存储(delta storage) 中维护增量版本(delta versions) 的序列。这一存储在MySQL和Oracle中被称为回滚段(rollback segment) ,在HyPer中也有使用。大部分已有的DBMS将元组的当前版本保存在主表中。为了更新已有的元组,DBMS会从增量存储中获取一个连续的空间,来创建新的增量版本。这一增量版本中包含被修改的属性的原始值而不是整个元组。随后,DBMS直接对主表中的master版本就地更新。
这一策略对修改元组属性的子集的UPDATE操作来说很理想,因为它减少了内存分配。然而这种方法在读敏感负载中会导致更高的开销。为了执行访问一个元组的多个属性的读操作,DBMS不得不遍历版本链以拉取该操作访问的每个属性的数据。
4.4 探讨 #
这些策略的不同特征影响了它们在OLTP负载下的表现。因此,这些策略中没有一个能在任何负载类型下都有最优的性能。仅追加策略在执行大规模扫描的分析查询中表现更好,因为不同版本在内存中连续存储,这能够减少CPU缓存的失配且很适合硬件的预取(prefetch)。但是访问元组较旧版本的查询有更高的开销,因为DBMS会顺着元组的版本链来查找适当的版本。仅追加策略还会将物理版本暴露给索引结构,这会造成额外的索引管理开销。
所有的这些存储策略都需要DBMS从中央数据结构中为每个事务分配内存(即表、增量存储)。多个线程会在同事访问并更新中央存储,因此这回导致访问竞争。为了避免这一问题,DBMS可以为每个中央数据结构(即表、增量存储)分别维护单独的内存空间,并以固定大小的增量扩展它们。随后每个工作线程将获取单独的内存空间。这本质上是对数据库分区,从而消除集中地争用点。
5. 垃圾回收 #
因为MVCC会在事务更新元组时创建新版本,如果不回收不再需要的版本,那么系统会耗尽空间。这还会增加查询执行的时间,因为DBMS会花更多的时间来遍历较长的版本链。因此,MVCC DBMS的性能高度依赖它垃圾回收(garbage collection,GC) 组件在确保事务安全的条件下回收内存的能力。
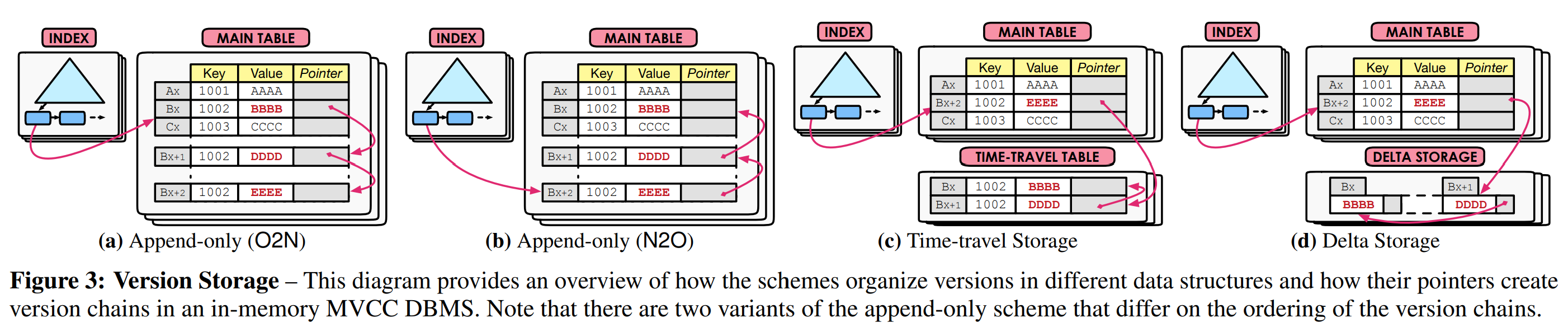
GC过程被分为三个步骤:(1)探测过期的版本(2)移除这些版本与和它们相关链及索引的链接(3)回收它们的存储空间。 如果一个版是无效的版本(即由被打断的事务创建)或对任何活动的事务都不可见,那么DBMS会认为该版本是过期的。对于后者,DBMS会检查版本的end-ts是否比所有活动的事务的$ T_{id} $都小。DBMS会维护一个中央数据结构来追踪这一信息,但是这会在多核系统中成为可伸缩性的一个瓶颈[27, 48]。
内存式的DBMS可以通过粗粒度的(coarse-grained)基于epoch(epoch-based)的内存管理来追踪被事务创建的版本已解决这一问题[44]。该方法中,系统总有一个活动的epoch和一个早期epoch的FIFO队列。在一定时间后,DBMS会将当前活动的epoch移动到早期epoch队列中,随后创建一个新的活动epoch。epoch的变换可以由后台线程执行,也可以由DBMS的工作线程以协作的方式执行。每个epoch都有对分配给它的事务数量的计数。DBMS会将每个新事务注册到活动的epoch中并增加其计数器。当事务完成时,DBMS将它从它的epoch中移除(其epoch可能已经不再是当前活动的epoch),并减小其计数器。如果一个非活动的epoch的计数器变为零且其之前的epoch也没有活动的事务了,那么DBMS可以安全地回收在这个epoch中被更新的版本。
MVCC中的GC有两种实现,它们的不同之处在于DBMS如何查找过期的版本。第一种方法是元组级(tuple-level) GC,DBMS会检验单个元组的可见性。第二种是事务级(transaction-level) GC,DBMS会检查被完成的事务创建的所有版本是否可见。需要注意的重要的点是,我们下面讨论的每个GC方案并非都与所有的版本存储策略兼容。
5.1 元组级垃圾回收 #
在这一方法中,DBMS会通过两种方法之一来检验每个单独的元组版本的可见性:
后台清理(Background Vaccuuming,VAC): DBMS使用后台线程定期扫描数据库以查找过期的版本。如表1所示,这时大多数MVCC DBMS中通用的方法,因为它实现起来很简单,且在所有的版本存储策略中都有效。但是这一机制无法为大型数据库伸缩,特别是GC线程数很少的数据库。一个更具有伸缩性的方法是,事务将无效的版本注册到无闩数据结构中[27]。随后GC线程使用之前描述的基于epoch的策略回收这些过期的版本。另一个优化是,DBMS维护脏块的bitmap,这样清理线程不需要检验从上一次GC后没被修改过的块。
协同清理(Cooperative Cleaning,COOP): 当执行事务时,DBMS会遍历版本链以定位可见的版本。在遍历时,它会识别过期的版本并将它们记录在全局数据结构中。这一方法的伸缩性很好,因为GC线程不再需要探测过期的版本,但是它只适用于O2N的仅追加存储。其一个额外的挑战是,如果事务不遍历某个元组的版本链,那么系统永远都不会移除其过期的版本。这一问题在Hekaton中被称为“灰尘角(dusty corners)”[16]。DBMS通过定期在一个单独的线程中执行类似VAC的完整GC来克服这一问题。
5.2 事务级垃圾回收 #
在这种GC机制下,DBMS会以事务级的粒度回收存储空间。这是用于所有的版本存储策略。当事务生成的版本对任何活动中的事务都不可见时,DBMS会认为该事务过期。在一个epoch结束后,所有被属于该epoch的事务生成的版本可以被安全地移除。这一策略比元组级GC策略更简单,且能与本地事务存储优化(transcation-local storage optimization)配合的更好(章节4.4),因为DBMS会立刻回收事务的存储空间。然而,这一方法的缺点是,DNMS需要为每个epoch追踪事务的读/写集合,而不是仅使用epoch的成员计数器。
5.3 探讨 #
使用后台清理的元组级GC是MVCC DBMS中最通用的实现方式。无论采用哪种方案,增加专用的GC线程数都可以加速GC过程。长时间运行的事务会导致DBMS性能下降。因为在这种事务的生命周期中生成的所有版本只有在该事务完成后才能被移除。
6. 索引管理 #
所有的MVCC DBMS都会将数据库的版本信息和它的索引分开。也就是说,索引中键存在意味着该键下的某个版本存在,但是索引条目不包含有关元组的哪个版本与之匹配的信息。我们定义一个索引条目(index entry) 为一个键值对(key/value pair),其中键 是元组的一个(或多个)有索引的属性,值 是指向该元组的指针。DBMS会沿着该指针找到元组的版本链,并扫描该版本链以定位对事务可见的版本。DBMS永远都不会从一个索引中得到“假阴性(false negative)”的结果(即收到键值对不存在的结果,但实际上键值对存在),但是可能会得到“假阳性(false positive)”的结果(即收到键值对存在的结果,但实际上键值对不存在),因为索引中的键指向的版本可能对某个事务不可见。
主键索引(primary key index)总是指向元组的当前版本。但是DBMS更新主键索引的频率取决于它的版本存储策略是否会在元组被更新时创建新版本。例如,在增量策略下,主键索引总是指向主表中元组的master版本,因此索引不需要被更新。对于仅追加策略,这取决于版本链的顺序:N2O要求DBMS在每当有新版本被创建时更新主键索引。如果元组的主键(译注:的值)被修改,那么DBMS会将该修改通过先DELETE再INSERT的方式应用到索引中。
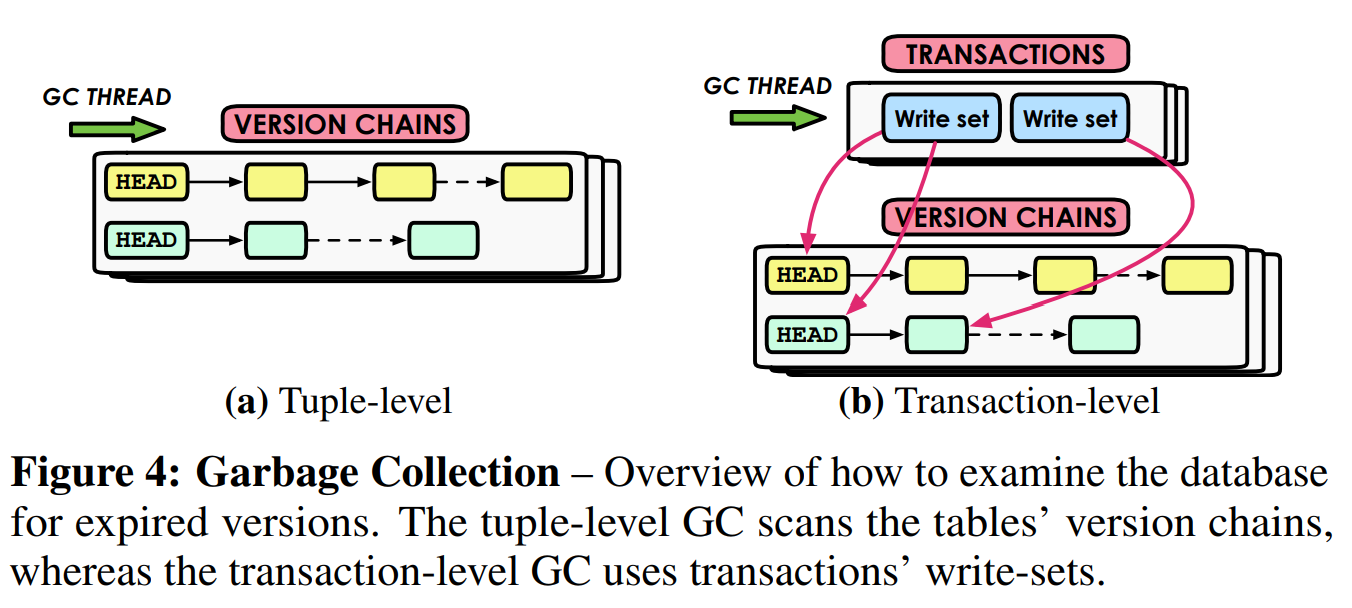
对于辅助索引(secondary index),这更为复杂,因为索引条目的键和指针都可以被修改。MVCC DBMS中的两种辅助索引管理策略与对这些指针的内容的管理策略有所不同。第一种方法使用了逻辑指针(logical pointers) ,其间接地映射到物理版本的位置上。与之相反的是物理指针(physical pointers) 的方法,其值就是元组的确切版本的位置。
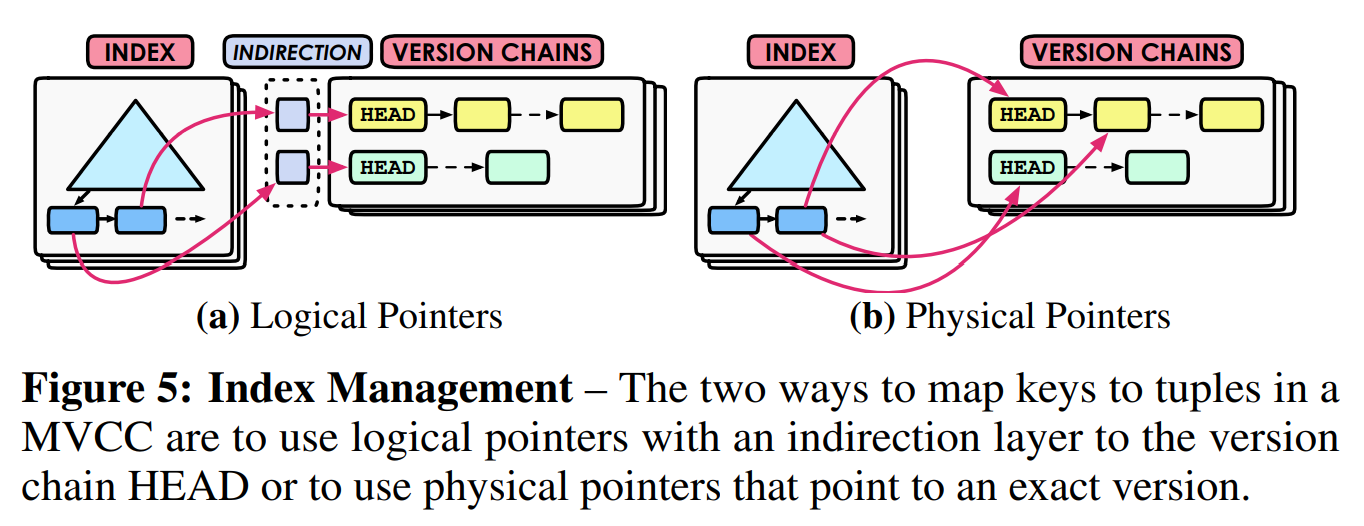
6.1 逻辑指针 #
使用逻辑指针的主要思想是,DBMS使用了固定的标识符,每个元组的索引条目的标识符不会改变。那么,如图5a所示,DBMS使用了一个将元组的标识符映射到其版本链链头的间接层。这避免了当元组被修改时(即使被索引的属性没被修改)必须更新一个表所有指向新物理地址的索引的问题。每次只需要修改映射条目。但是因为索引指向确切的版本,DBMS需要从版本链的链头开始遍历来找到可见的版本。这种方法适用于所有的存储策略。就我们目前讨论的来说,这一映射的实现有两种选择:
主键(Primary Key,PKey): 在这种方法中,标识符和对应的元组的主键相同。当DBMS从辅助索引中检索到一个条目时,它会在表的主键索引中执行另一次查找,来定位版本链的链头。如果辅助索引的属性与主键有重叠,那么BDMS不必在每个条目中保存完整的主键。
元组Id(Tuple Id,TupleId): Pkey指针的一个缺点是,随着元组主键的增长,数据库的存储开销会越来越大,因为每个辅助索引都有主键的一份完整的拷贝。除此之外,因为大多数数据库的主键索引都使用一种“保序(order-preserving)”的数据结构,所以执行额外的查找的开销取决于条目的数量。另一种方式是,使用一个唯一的64位元组标识符替代主键,并使用一个独立的无闩哈希表来维护到元组版本链链头的映射信息。
6.2 物理指针 #
在第二种策略下,BDMS在索引条目中保存版本的物理地址。这种方法仅适用于仅追加存储,因为DBMS会将版本保存到同一张中,所以所有索引都能指向这些版本。当更新表中任何元组时,DBMS会将新创建的版本插入到所有的辅助索引中。通过这种方式,DBMS不需要比较辅助索引和所有索引的版本,就能够从辅助索引中搜索元组。如MemSQL和Hekaton的一些MVCC DBMS就采用了这一策略。
6.3 探讨 #
和其它设计决策类似,这些索引管理策略在不同负载下的表现各异。逻辑指针的方法更适用于写入敏感型负载,因为DBMS只需要在事务修改索引的属性时才需要更新辅助索引。然而,读取可能会变慢,因为DBMS会遍历版本链并执行额外的键比较。而物理指针的方法更适用于读取敏感型负载,因为索引条目会指向确切的版本。但是对于更新操作来说这样会更慢,因为该策略需要DBMS讲每个新版本插入到所有的辅助索引中,这会使更新操作变得更慢。
最后,一个很有趣的点是,除非元组的版本信息嵌入在每个索引中,否则在MVCC DBMS中不可能仅使用索引进行扫描。系统必须始终从元组本身中检索这一信息,以确定每个元组的版本是否对某个事物可见。NuoDB通过将头部的元数据与元组数据分开保存的方式,减少了版本检查时读取的数据总量。
7. 实验分析 #
我们现在将给出对本文中我们讨论的事务管理设计决策的分析。我们付出了很多努力来在Peloton DBMS[5]中实现了每种设计的最先进的版本。Peloton将元组保存在基于行(row-oriented)的无序内存堆中。它使用了libcuckoo[19]哈希表作为它的内部数据结构,并使用Bw-Tree[32]作为数据库索引。我们还使用了无闩变成技术[15]来优化Peloton的性能。我们将所有的事务作为在SERIALIZABLE隔离级别下的存储过程执行。Peloton使用了基于epoch的内存管理(见第五章),我们将它的epoch配置为40ms[44]。
我们将Peloton部署在了4插槽的Intel Xeon E7-4820服务器上,它有128GB的DRAM,运行64位Ubuntu 14.04操作系统。每个插槽上有10个1.9GHz的核心和25MB的L3缓存。
我们首先比较了并发控制协议。然后选择了总体上最佳的协议,用它来评估版本存储、垃圾回收、和索引管理策略。对于每个实验,我们执行了60秒的负载让DBMS热身,然后再执行120秒的负载来测量吞吐量。我们为每个实验执行5次,并汇报平均执行时间。我们在第八章中总结了我们的发现。
7.1 Benchmarks #
接下来,我们将描述在我们的评估中使用的负载。
YCSB: 我们队YCSB[14] Benchmark进行了修改,以对OLTP应用程序在不同工作负载下的配置进行建模。数据库包含一个有一千万个元组的表,每个元组有64位主键和64位整型属性。每个操作相对独立,也就是说,操作的输入不依赖之前操作的输出。我们使用了三种负载的混合来让每个事务的读取或更新操作的次数不同:(1)只读(100%读取)(2)读取敏感型(80%读取、20%更新)(3)更新敏感型(20%读取、80%更新)。我们还让对元组的读取或更新操作的属性数不同。访问元组的操作服从Zipfan分布,该分布受一个参数($ \theta $)控制,该参数影响争用量(contention)(即倾斜,skew),当$ \theta = 1.0 $时表示最高的倾斜配置。
TPC-C: 该benchmark目前是测量OLTP系统性能的标准负载[43]。它建模了一个有9张表和5种事务类型的中心仓库订单处理程序。我们修改了原始的TPC-C负载,使其包括一种新的表扫描查询StockScan,它会扫描Stock表并计数每个仓库中项的个数。整个负载的争用量由仓库的个数控制。
7.2 并发控制协议 #
首先我们比较使用了第三章中的并发控制协议的DBMS的性能。对于串行验证者策略,我们在快照隔离上实现了SSN(SI+SSN)[45]。我们让DBMS固定使用(1)N2O顺序的仅追加存储(2)事务级GC(3)逻辑映射索引指针。
首先,我们的实验使用YCSB负载来评估协议。我们首先调研了阻碍这些协议扩展的瓶颈。然后通过不同的负载争用比较了它们的性能。之后,我们展示了每种协议在处理既包括读写事务又包括只读事务的异构负载时的表现如何。最后,我们使用了TPC-C benchmark来每种协议在真实负载下的表现。
伸缩性瓶颈(Scalability Bottlenecks): 本实验展示了协议在高线程数时的表现。我们通过配置,让只读YCSB负载执行的事务既有很短的(每个事务只有一个操作)也有很长的(每个事务有100个操作)。我们使用了较低的倾斜因子,并扩展线程数。
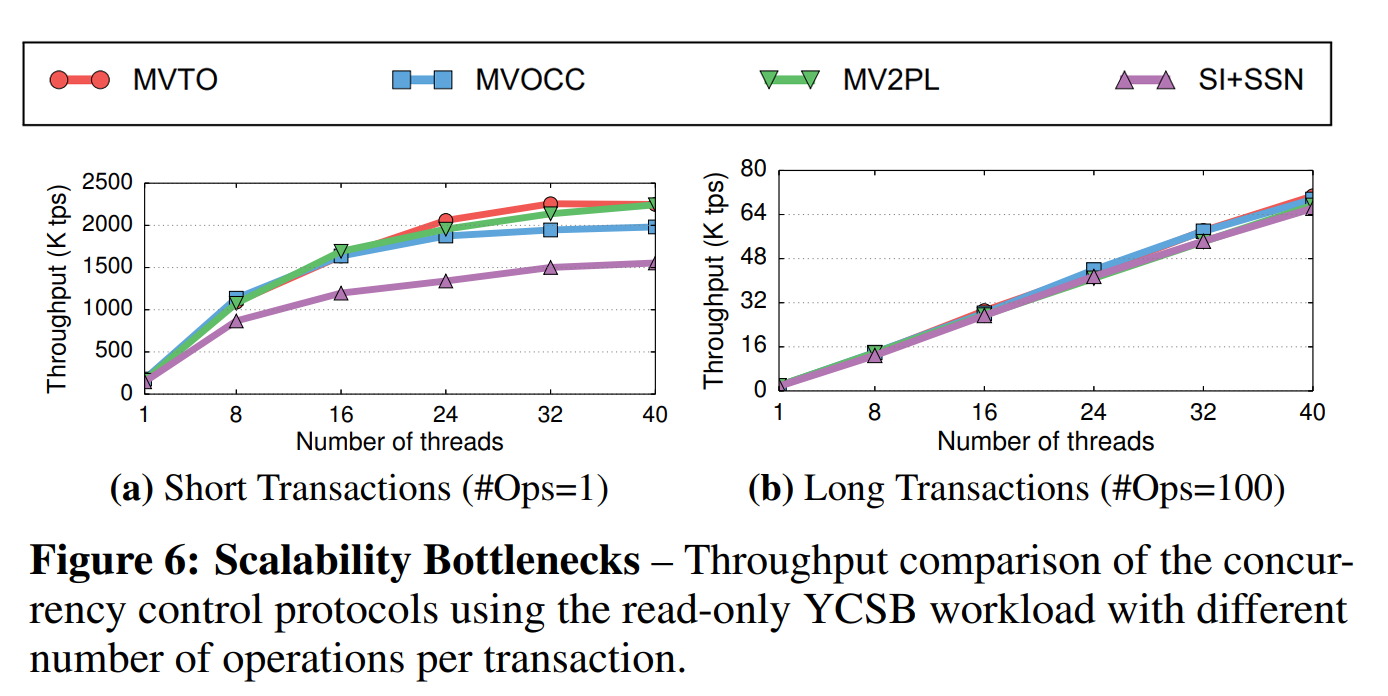
短事务负载导致了图6a中展示的结果,所有的协议几乎都能线性地伸缩到24线程。所有的这些协议的主要瓶颈是缓存一致性(coherence)流量,这些流量来自于更新内存管理器的计数器和在事务提交时检查冲突的流量(尽管事务中没有写入)。SI+SSN性能低的原因在于,它为了追踪事务维护了一个中央哈希表。通过预分配与复用事务上下文结构[24]的方式可以移除该瓶颈。当我们把事务长度增加到100个操作时,如图6b所示,协议的吞吐量减小了高达30倍,但是能够线性地伸缩到40线程。这符合预期,因为执行的事务变少时,对DBMS中心数据结构的争用就减少了。
事务争用(Transaction Contention): 接下来,我们在不同的争用级别下比较了这些协议。我们固定DBMS的线程数为40。我们使用了每个事务有10个操作的读取敏感型和更新敏感型负载。我们在每个负载的事务访问模式中使用了不同的争用级别($ \theta $)。
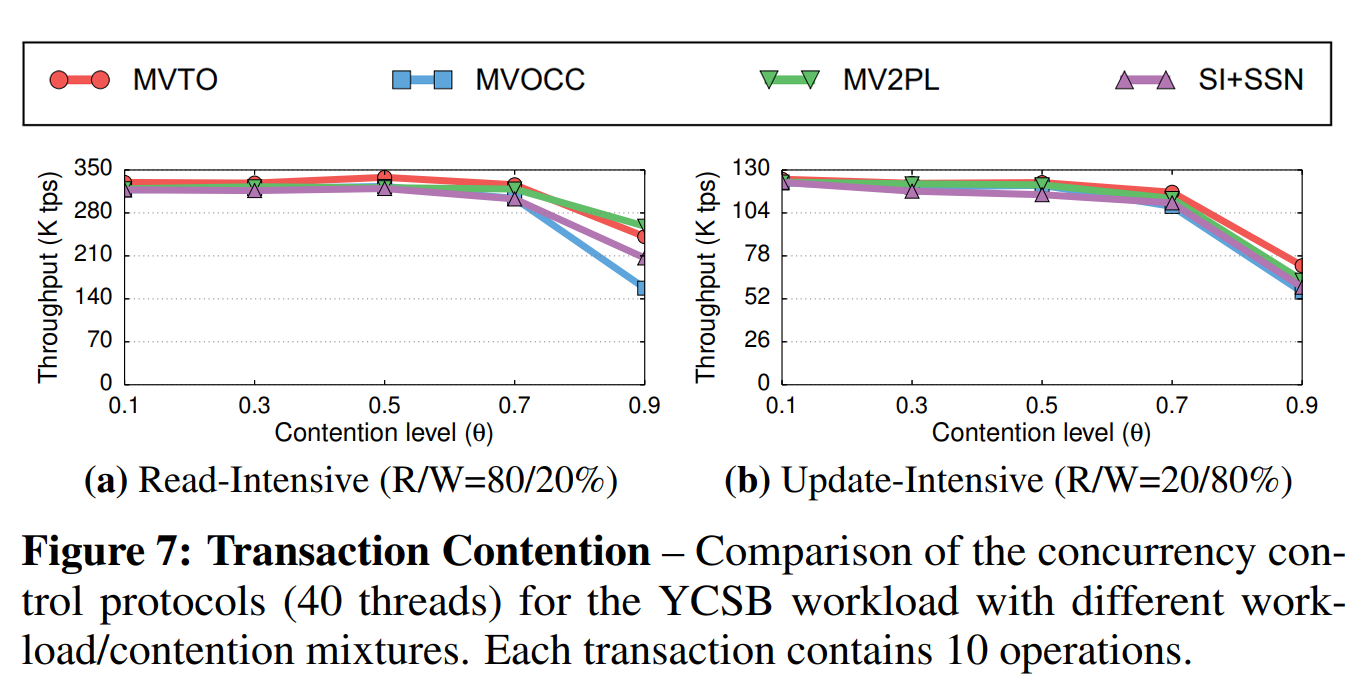
图7a展示了读取敏感型负载下的DBMS吞吐量。当$ \theta $小于0.7时,我们可以看到所有的协议的吞吐量相似。当超过该争用级别时,MVOCC的性能减小达50%。这是因为MVOCC直到事务已经执行了其操作时,才能发现事务会因冲突而被打断。多版本策略在这一情况下没有优势。如图7b所示,尽管在争用增加时,我们在更新敏感负载的结果中能看到相同的性能下降,但是除了MV2PL之外,这些协议都没有太大的区别。除了MV2PL之外的这些协议除了“写入-写入”冲突的方法相似,同样,多版本策略对于减少这类冲突没有帮助。
异构负载(Heterogeneous Workload): 在接下来的这个实验中,我们评估了异构YCSB负载,该负载由读写和只读的SERIALIZABLE事务混合而成。每个事务包含100个操作,每个操作访问一个不同的元组。
DBMS使用了20个线程来执行读写事务,我们使用不同的线程数来专门处理只读的查询。所有操作的访问模式的分布都采用了很大的争用配置($ \theta = 0.8 $)。我们首先在让应用程序预先没有声明查询是“只读的”的情况下执行了该负载,然后让应用程序预先声明查询是“只读的”再次执行一次。
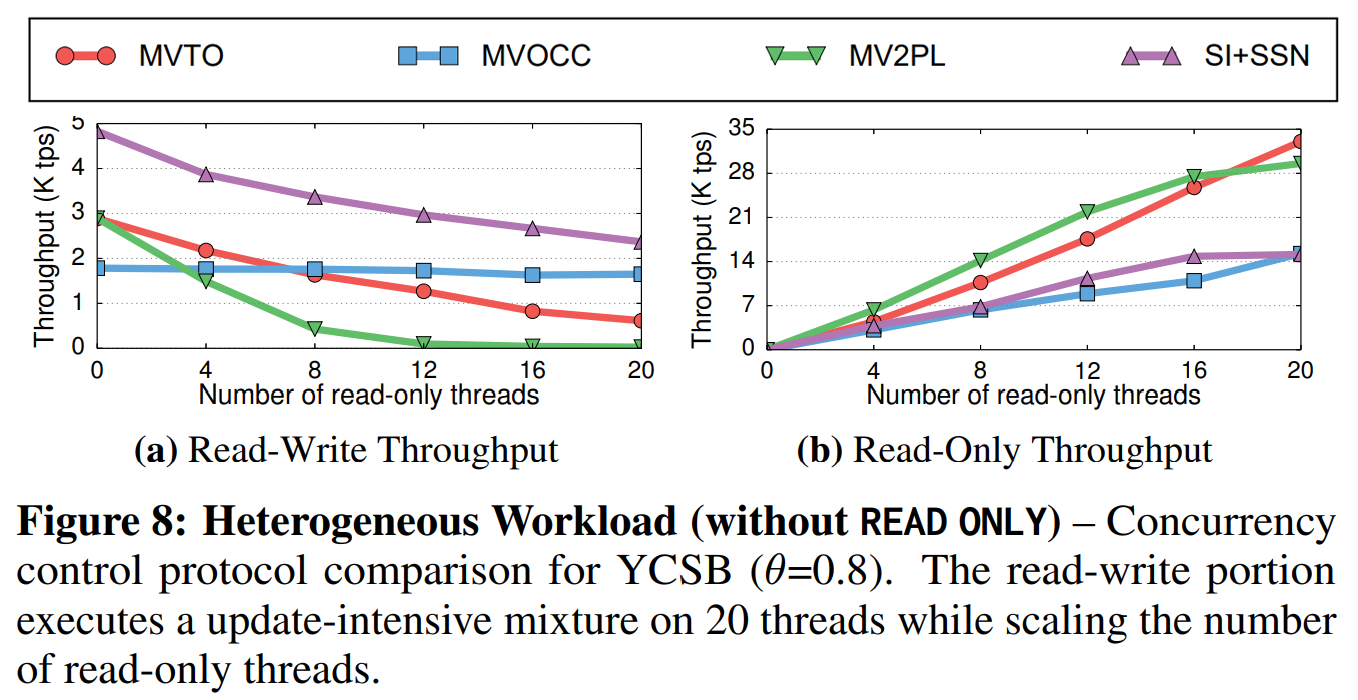
在程序不预先声明只读查询时,有很多有趣的趋势。第一,随着只读线程数增加,MVTO和MV2PL协议中读写事务的吞吐量下降(如图8a所示),而只读事务的吞吐量上升(如图8b所示)。这是因为这些协议平等地对待读取和写入。因为任何读取或写入一个元组的事务会阻塞其它访问同一个元组的事务,只读查询数量的增加导致了读写事务被打断的概率更高。因为这些冲突,MV2PL在只读线程增加到20时仅完成了少量的事务。第二,尽管随着只读线程数增加,MVOCC协议在读写部分达到了稳定的性能,但是它们在只读部分的性能分别比MVTO低了2倍和28倍。因为MVOCC没有读取锁,这导致只读队列长时间不会被执行(译注:原文为“starvation”)。第三,SI+SSN读写事务性能高出很多。这是因为它减少了DBMS因精确的一致性验证打断事务的概率。
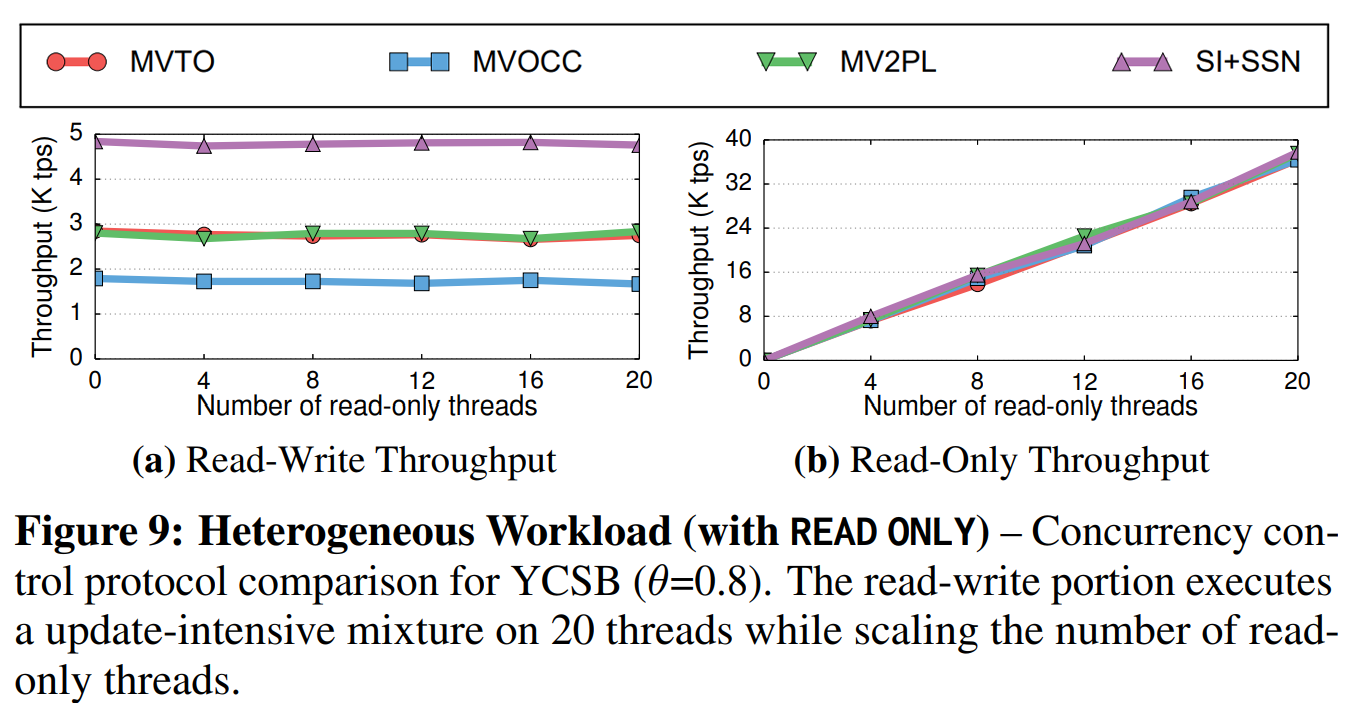
图9中的结果显示,当负载预先声明了只读部分时,各种协议的表现不同。第一,如图9b所示,他们的只读吞吐量相同,因为DBMS在执行这些查询的时候不会检查冲突。且如图9a所示,当只读查询与读写事务隔离时,它们对读写事务的吞吐量很稳定,因此执行这些只读事务不会增加数据争用。SI+SSN的表现再次成为了最好的,因为它减少了打断的概率,它比NV2PL和MVTO快了1.6倍。而MVOCC的性能最差,因为它因验证失败的打断率最高。
TPC-C: 之后,我们使用了将仓库数设置为10的TPC-C benchmark比较了这些协议。这一配置产生了很高的争用负载。
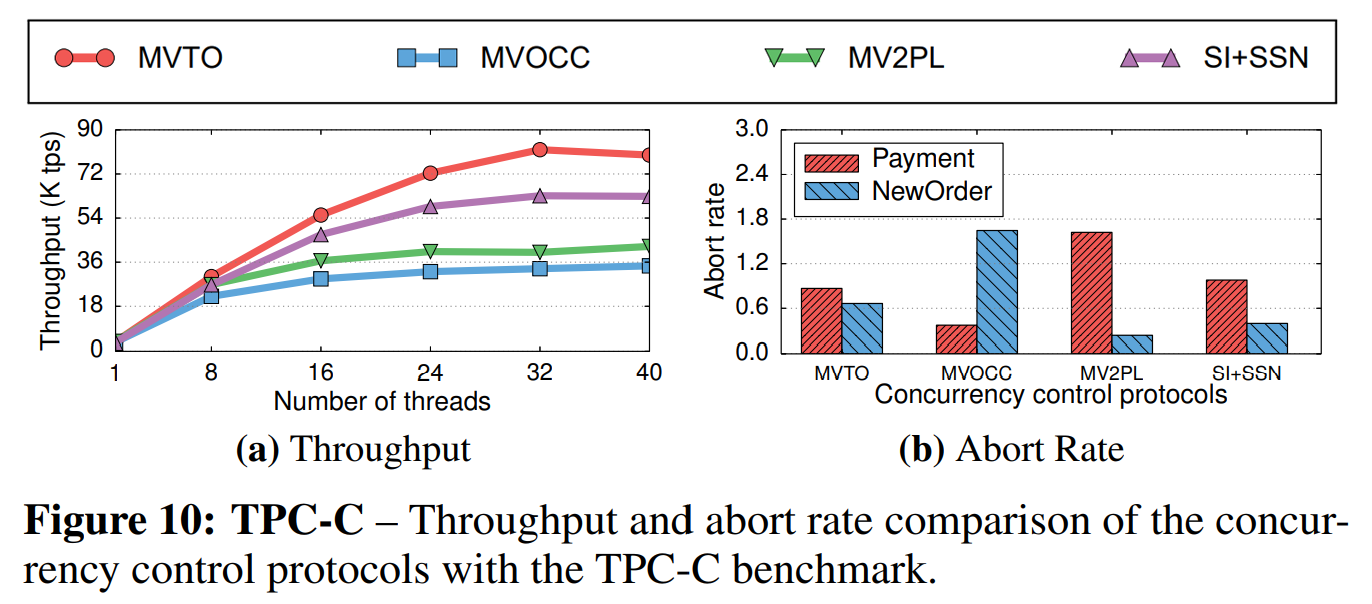
如图10a所示,与其它协议相比,MVTO的性能高出了了45%~120%。SI+SSN生成的吞吐量比其它的协议都高,因为它需要检测反依赖,而不是通过类似OCC的一致性检查盲目地打断。MVOCC造成了计算的浪费,因为它近在验证阶段检测冲突。在图10b中,更有趣的是,不同的协议打断的事务也不同。MVOCC更有可能打断NewOrder事务,而在MV2PL中,Payment被打断的概率比NewOrder高出了6.8倍。这两种事务访问同一张表,同样,乐观的协议仅在NewOrder事务的验证阶段检测读取冲突。SI+SSN因为有反依赖追踪,所以它的打断率低;而在MVTO中,因为分配给每个事务的时间戳直接决定了它们的顺序,所以它能够避免错误的打断。
7.3 版本存储 #
接下来我们评估DBMS的版本存储策略。首先,我们分析了仅追加存储中非内联属性的存储机制。然后,我们讨论了版本链的顺序是如何影响仅追加存储的DBMS的性能的。接下来,我们通过使用不同的YCSB负载,将仅追加策略与时间旅行策略和增量策略进行了比较。最后,我们使用TPC-C benchmark再次比较了这些策略。在所有的这些实验中,我们让DBMS都使用了MVTO协议,因为它在之前的实验中有最均衡的性能。
非内联属性(Non-Inline Attributes): 第一个实验评估了在仅追加存储中保存非内联属性的不同机制的性能。在本实验中,我们使用了混合的YCSB负载,数据库变为包含了一个有一千万个元组的表,每个元组有一个64位主键和不同数目的用100字节的非内联VARCHAR类型表示的属性。我们在40个线程中使用了低争用因子($ \theta = 0.2 $)的读取敏感型和更新敏感型负载,其中每个事务执行10个操作。每个操作仅访问元组中的一个属性。
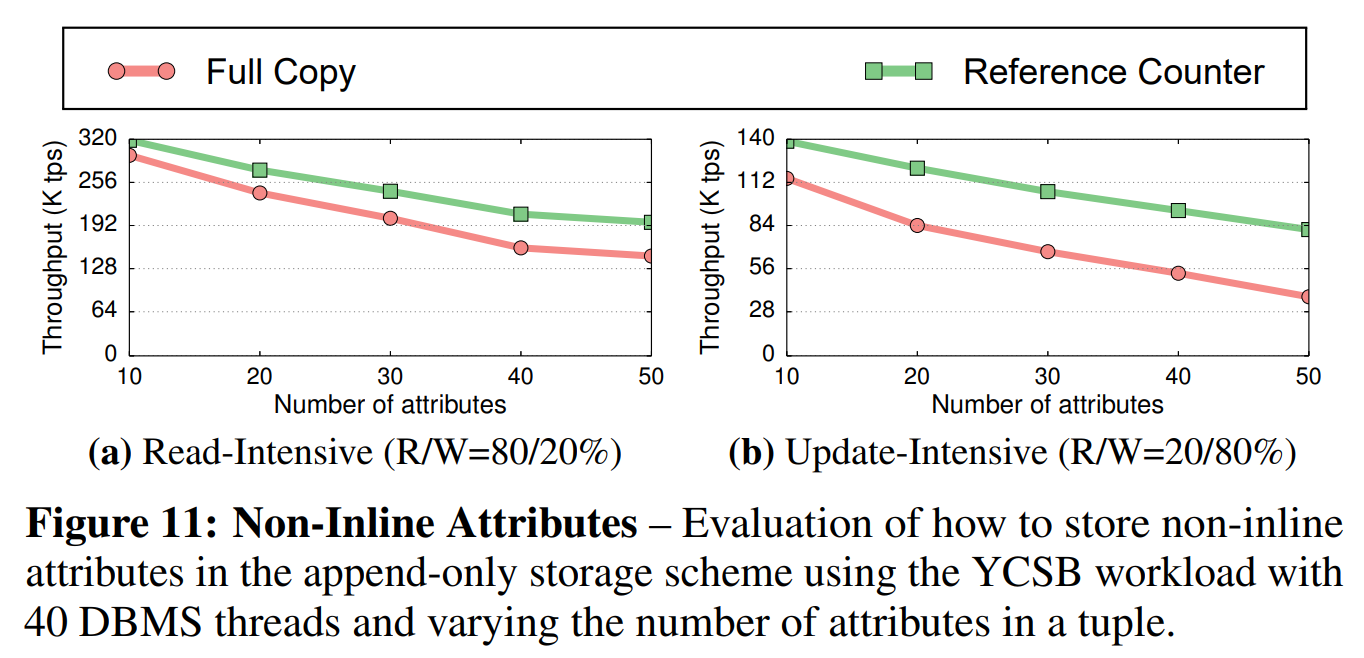
图11表明,为没被修改的非内联属性维护引用计数器总是会有更好的性能。在读取敏感型负载下,当有这些计数器的非内联属性的个数增加到50个的时候,DBMS的吞吐量比常规的“完整元组拷贝(full-tuple-copy)”策略高出了多达40%。这是因为DBMS避免了更新操作中的冗余数据拷贝。这一差异在更新敏感型负载下更为突出,其性能差异超过了100%,如图11b所示。
版本链顺序(Version Chain Ordering): 第二个实验测量了在章节4.1描述的N2O和O2N的版本链顺序的性能。我们使用了事务级的后台清理GC,并在YCSB混合负载下比较了不同的顺序。我们将事务的长度设为10。我们固定了DBMS的线程数为40,并使用了不同的负载争用等级。
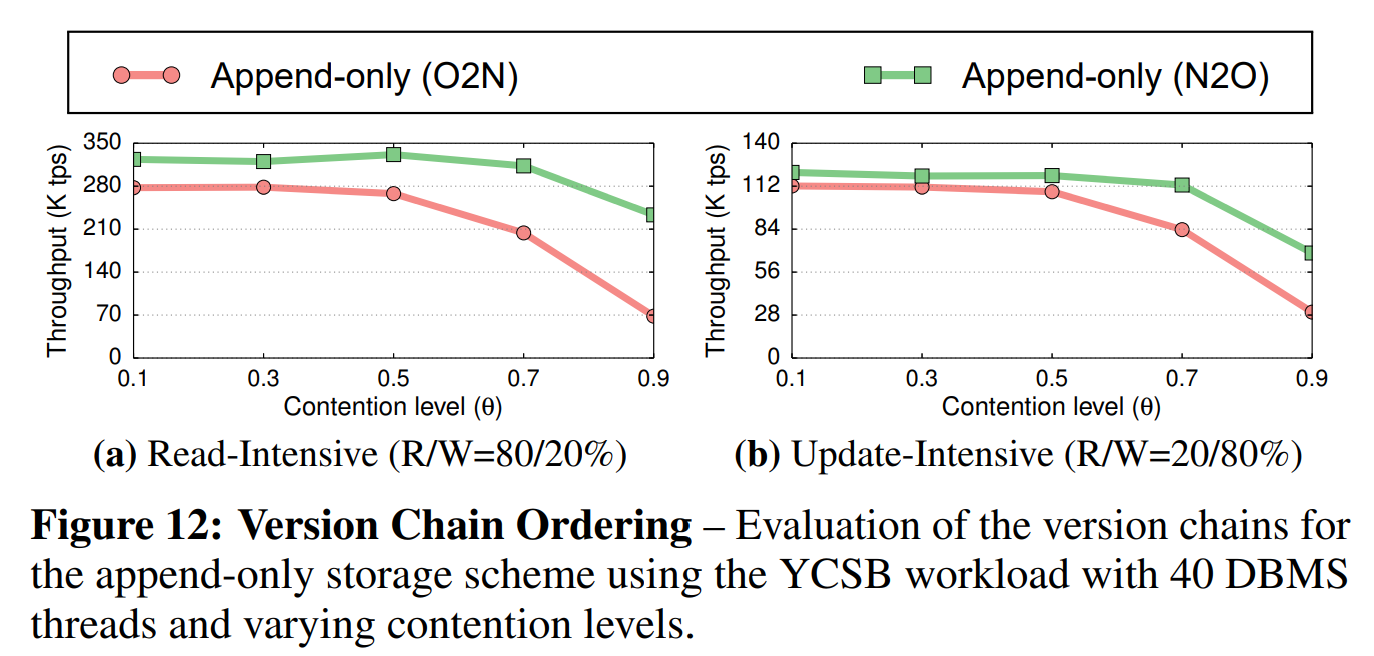
如图12所示,在两种负载下,N2O顺序的性能总是比O2N的好。尽管DBMS会为每个新版本更新索引的指针,但是这与O2N遍历更长的链的开销相比相形见绌。版本链长度的增加意味着事务需要执行更长时间,从而增大了一个事务与另一个事务冲突的可能性。这种现象在最高的争用级别下($ \theta = 0.9 $)更为明显,其中N2O顺序的性能达到了2.4~3.4倍。
事务占用(Transaction Footprint): 在下一项存储策略的对比中,我们在元组中使用了不同的属性数。我们在40个线程上使用了低争用的($ \theta = 0.2 $)的YCSB负载,其中每个事务执行10个操作。每个读取或更新操作仅访问或修改元组中的一个属性。我们使用了N2O顺序的仅追加存储。对于所有的版本存储策略,我们都分别分配了单独的内存空间,以减少内存分配的开销。
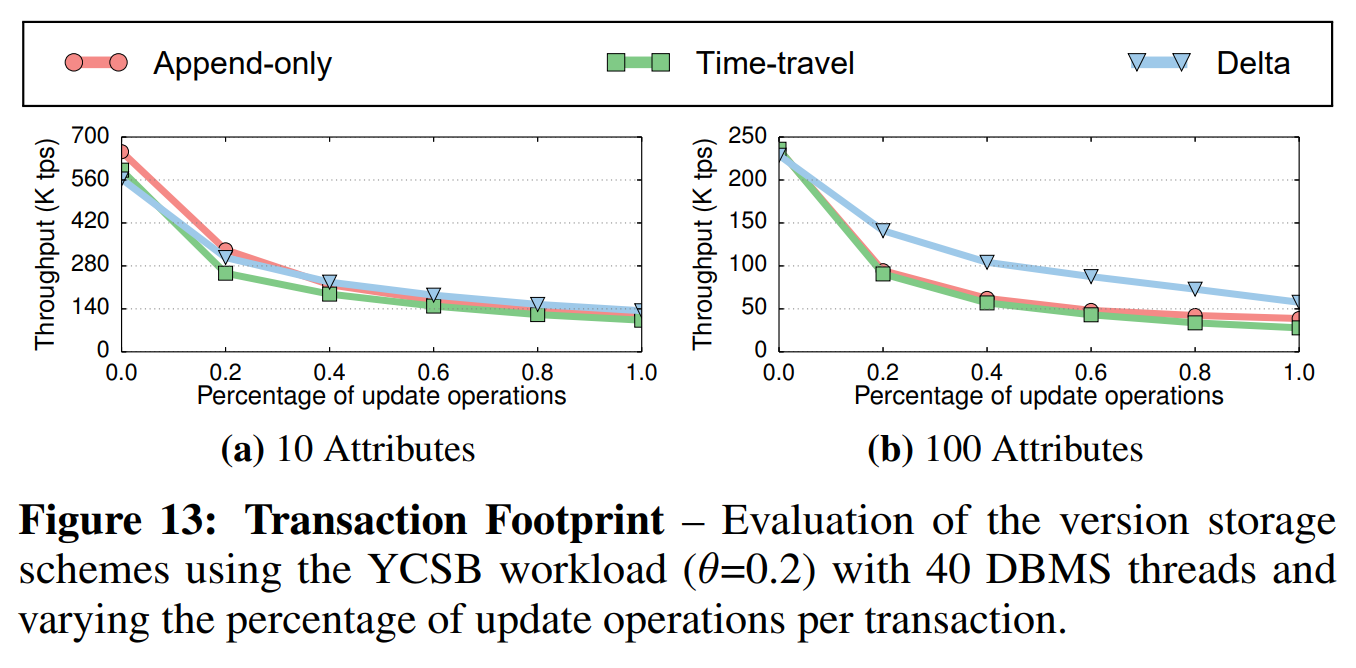
如图13a所示,在表有10个属性时,仅追加策略和增量策略的性能相似。同样,仅追加策略和时间旅行策略的吞吐量几乎相同。图13b的结果表明,当表有100个属性时,查分策略的性能达到了仅追加策略和时间旅行策略的2倍,因为它使用的内存更少。
属性修改(Attributes Modified): 我们将表中的属性数量修改到100,并在事务的每个更新操作中修改不同数量的属性。我们在40个线程上使用了低争用因子($ \theta = 0.2 $)的读取敏感型负载和更新敏感型负载,每个事务执行10个操作。像之前的实验一样,每个读操作访问一个属性。
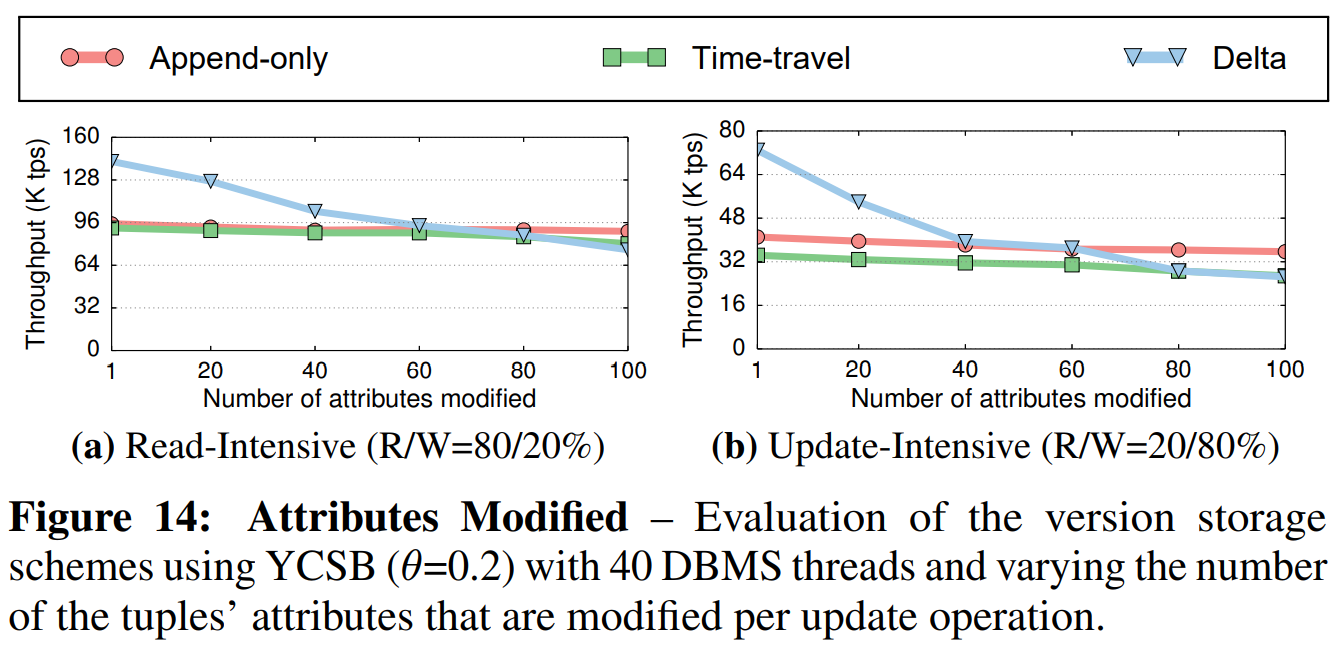
如图14所示,无论修改的属性数量如何,仅追加策略和时间旅行策略的性能都很稳定。正如预期的一样,当修改的属性的数量很少时,增量策略的性能最好,因为它对每个版本拷贝的数据更少。但是随着更新操作的范围扩大,它的性能就与其它的相同,因为每个增量数据拷贝的数据量相同。

为了测量属性修改对读取的影响如何,我们在每个操作中访问了不同数量的属性。如图15a所示,当更新操作仅修改一个(随机的)属性时,读取的属性数的增加大幅影响了增量策略。这是符合预期的,因为DBMS必须用更多的时间遍历版本链以搜索目标列。仅追加存储和时间旅行存的性能也会下降,因为内部的socket通信开销与每个读操作访问的总数据量成正比地增长。这与图15b中观察到的结果一致,其中,更新操作会修改元组的所有属性,每个读操作访问的属性的增加会导致所有存储策略的性能下降。
内存分配(Memory Allocation): 接下来的实验评估了内存分配会如何影响版本策略的性能。我们在40个线程上使用了低争用因子($ \theta = 0.2 $)的YCSB负载。每个事务执行10个操作,每个操作仅访问元组中的一个属性。我们改变了不同的内存空间的个数,并测量DBMS的吞吐量。DBMS每次按512KB大小扩展内存空间。
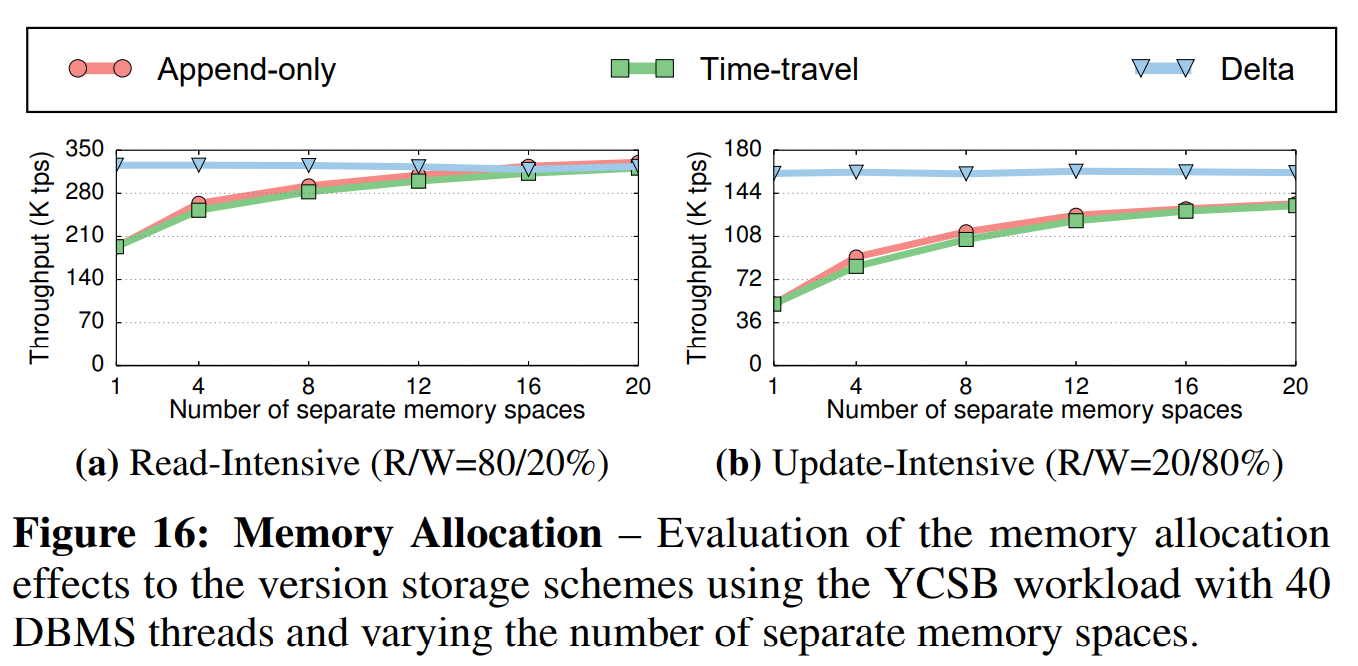
如图16所示,无论DBMS分配的内存空间数如何,增量存储策略的性能都很稳定。相反,随着内存空间的数量从1个增加到20个时,仅追加策略和时间旅行策略的吞吐量的吞吐量提高了1.6~4倍。这是因为增量存储仅拷贝元组中被修改的属性,其需要的内存总量有限。相反,另外两种存储策略会频繁获取新的槽来保存每个新增的元组版本的完整的拷贝,这增加的DBMS内存分配的开销。
TPC-C: 最后,我们使用TPC-C比较了不同的策略。我们设置仓库的数量为40,并逐渐增大线程数来测量整个系统的吞吐量和StockScan查询的延迟。
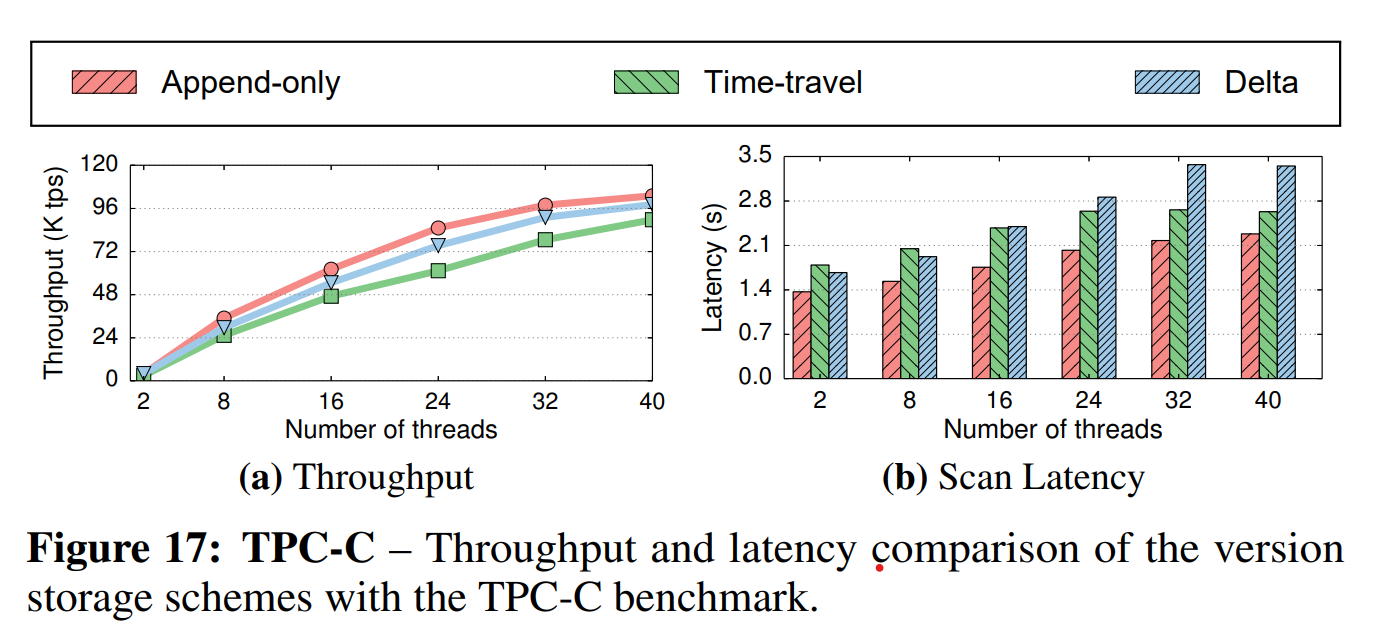
如图17a中的结果所示,仅追加存储比其它两种策略有更好的性能。这是因为该策略在执行多属性读操作时的开销更小,这种操作在TPC-C benchmark中很普遍。尽管增量数据存储在创建新版本时分配的内存更少,这一优势并没有带来显著的性能提升,因为在我们的实现中我们通过维护多个内存空间优化了内存管理。时间旅行策略的吞吐量更低,因为它没有为读取或写入操作带来任何好处。在图17b中,我们可以看到,仅追加策略和时间旅行策略在表扫描查询中表现更好。在增量存储策略下,扫描查询的延迟随着线程数的增长近线性地增长(这是不好的),而仅追加策略和时间旅行策略在使用40个线程时延迟降低了25%~47%。
7.4 垃圾回收 #
现在我们将对第五章中介绍的GC机制进行评估。在这些实验中,我们使用了MVTO并发控制协议。首先我们比较了元组级的后台清理和协同清理。然后我们将元组级的方法与事务级的方法进行了对比。
元组级比较(Tuple-level Comparison): 我们使用了低争用因子和高争用因子的更新敏感型负载(每个事务10个操作)。DBMS使用了O2N顺序的仅追加存储,因为COOP仅适用于这一顺序。在我们的配置中,DBMS使用40个线程处理事务,使用1个线程做GC。我们给出了DBMS的吞吐量随时间的变化和系统中新分配的内存总量。为了更好地理解GC的影响,我们还在禁用GC的情况下执行了负载。
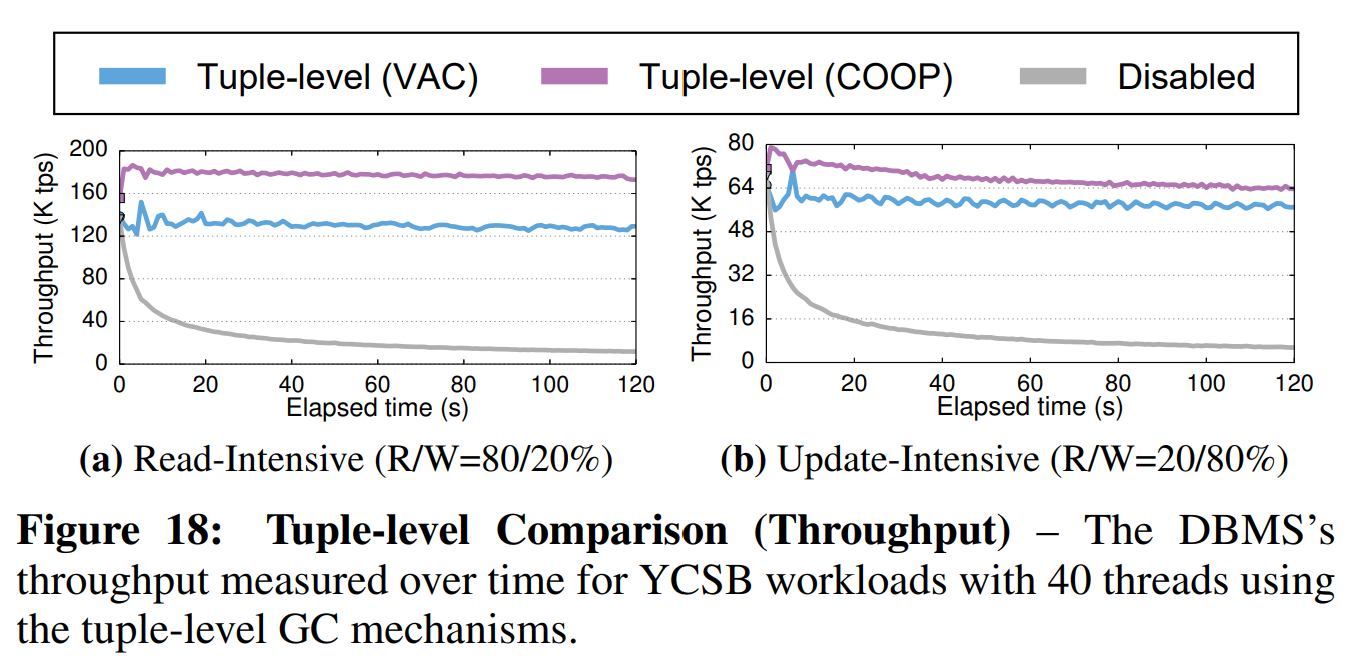
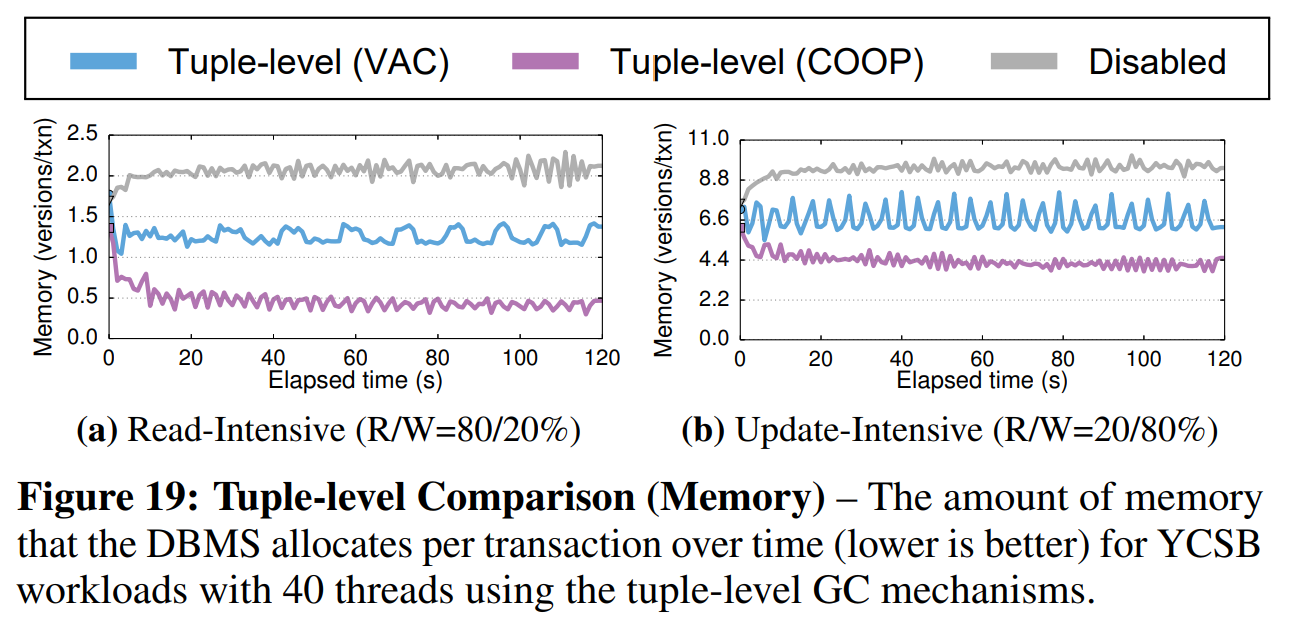
图18中的结果显示,在读取敏感负载下,COOP的吞吐量比VAC高出了45%。在图19中,我们可以看到,COOP中每个事务的内存占用比VAC少30%~60%。与VAC相比,COOP的性能更加稳定,因为它可以将GC的开销分摊到多个线程上,且内存回收更快。在两种负载下,我们都能看到,当GC被禁用时,性能会随着时间下降,因为DBMS需要遍历更长的版本链以检索版本。另外,因为系统永远不会回收内存,它需要为每个新版本分配新内存。
元组级vs事务级(Tuple-level vs. Transaction-level): 下面,我们评估在执行两种YCSB负载(高争用因子)的混合时,使用元组级和事务级机制的DBMS的性能。在我们的配置下,DBNS使用N2O顺序的仅追加存储。我们将工作线程数设置为40,并使用1个线程来做后台清理(VAC)。我们还在使用40个线程但没有任何GC的配置下执行了相同的负载。
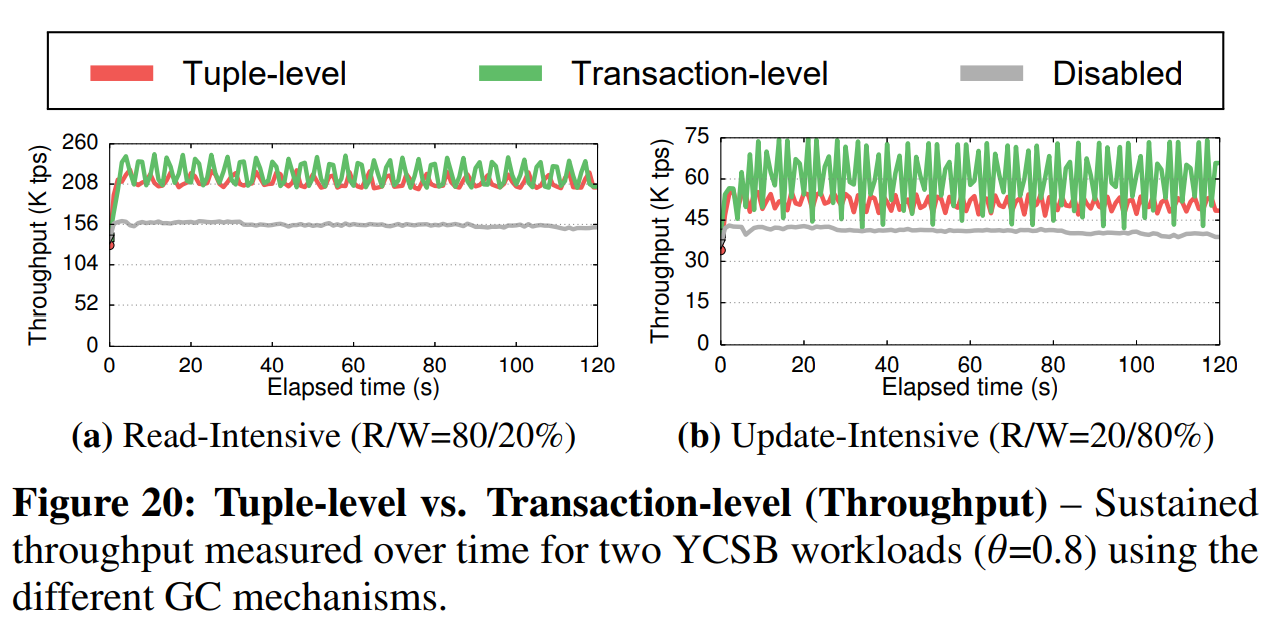

图20a中的结果显示,对于读取敏感型负载,事务级GC的性能比元组级GC的性能稍微好了一点,但在图20b的更新敏感型负载下,性能的差距增大到了20%。事务级GC会分批移除过期的版本,这减少了同步开销。与禁用GC的情况相比,两种机制的吞吐量都提高了20%~30%。如图21所示,两种机制都减少了内存使用量。
7.5 索引管理 #
最后,我们比较了第六章中描述的索引指针策略。影响使用这些策略的DBMS的性能的主要方面是辅助所以。每当创建新版本时,DBMS就要更新指针。因此,我们在更新敏感型YCSB负载下,评估了这些策略随着数据库中辅助索引数增加时的性能表现。在所有试验的配置下,DBMS都使用了MVTO并发控制协议、N2O顺序的仅追加存储、和事务级COOP GC。我们使用仅追加存储的原因在于它是唯一支持物理索引指针的策略。对于逻辑指针,我们将每个索引键映射到了版本链链头。
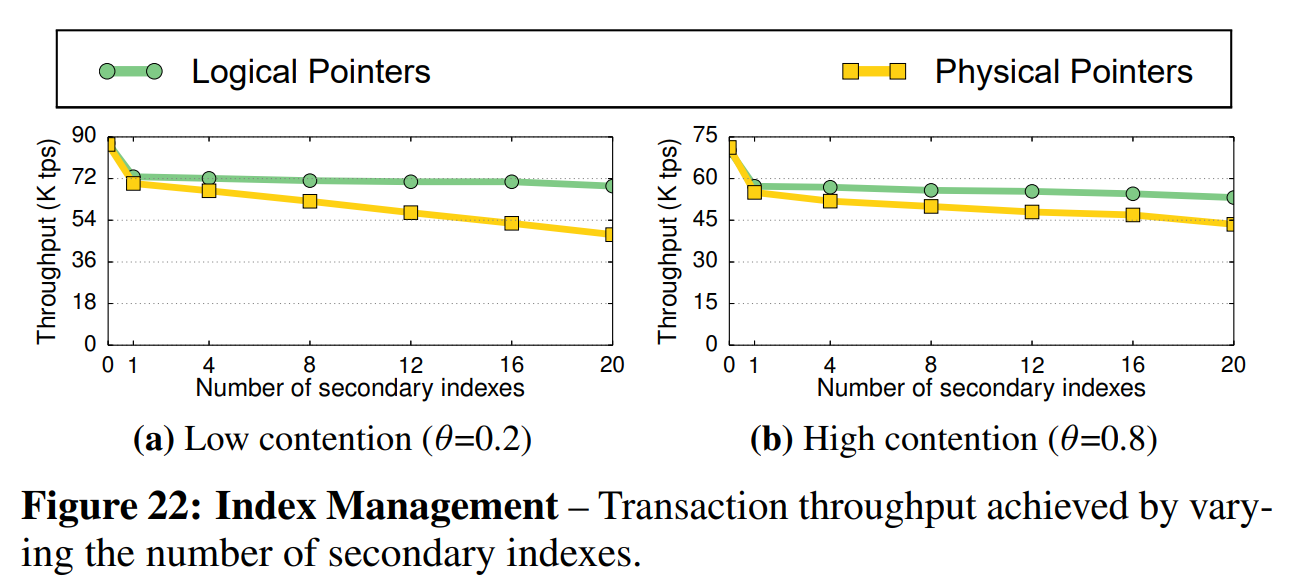
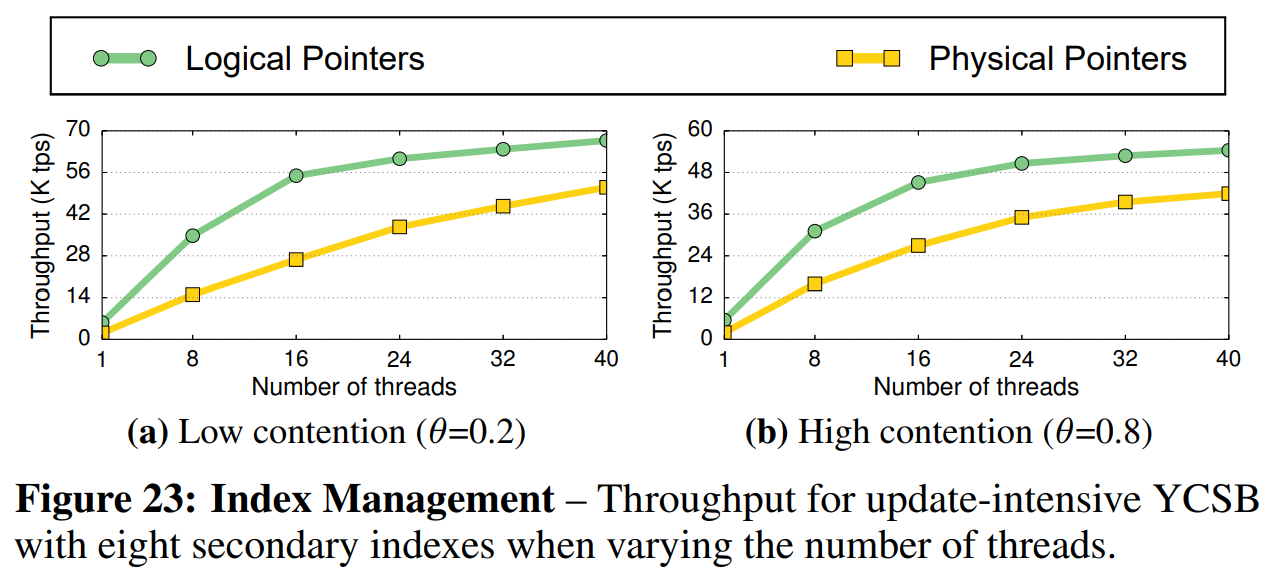
图22b中的结果表明,在高争用因子下,逻辑指针策略的性能比物理指针策略高出了25%。图22a中的结果表明,在低争用因子下,随着辅助索引数增加到20个,性能差距增大到了40%。图23进一步展示了逻辑指针的优势。其结果表明,在高争用负载下,使用逻辑指针的DBMS吞吐量比使用物理指针的高出45%。无论是在低争用因子下还是在高争用因子下,性能的差距都会醉着线程数的增加而下降。
8. 探讨 #
我们在对MVCC DBMS中的这些事务管理设计策略的分析与实验中得出了4个发现。最重要的是,版本存储策略是多核环境下内存式MVCC DBMS伸缩性最重要的组件之一。这违背了传统的数据库研究中的常识,传统的数据库研究通常侧重于并发控制协议的优化[48]。我们观察到,仅追加策略和时间旅行策略的性能受下层内存分配策略的效率影响;主动为每个核划分内存空间可以解决这一问题。无论使用怎样的内存分配策略,增量存储策略都能保持相对较高的性能,特别是当只修改表中保存的属性的子集的时候。但是该策略表扫描性能很低,且可能不适合读取量很大的分析负载。
我们还发现,使用适合负载的并发控制协议能够提高性能,特别是在高争用的负载下。章节7.2的结果表明,协议的优化可能对这些负载下的性能有负面影响。总之,我们发现MVTO在各种负载下的表现都很好。我们在表1中列出的系统都没有使用这一协议。
我们还观察到MVCC DBMS的性能与GC的实现密切相关。特别是,我们发现事务级GC能提供最好的性能和最少的内存占用。这是因为它回收过期元组版本的同步开销比其它方法小。我们注意到,GC过程可能导致系统的吞吐量和内存占用波动。
最后,我们发现,对于构建了许多辅助索引的数据库来说,索引管理策略也会影响DBMS的性能。章节7.5的结果显示,逻辑指针策略总能达到更高的吞吐量,特别是当处理更新敏感型负载时。这证实了工业界中对这一问题的报告[25]。
为了验证这些发现,我摩恩在Peloton中做了最后一个实验,我们配置Peloton使用表1中列出的MVCC配置。我们执行了TPC-C负载,并使用一个线程反复执行StockScan查询。我们测量了DBMS的吞吐量和StockScan查询的平均延迟。虽然在真实地DBMS中有我们没比较的其它因素(例如,数据结果、存储架构、查询编译等),但这仍是对它们的能力的很好的近似。
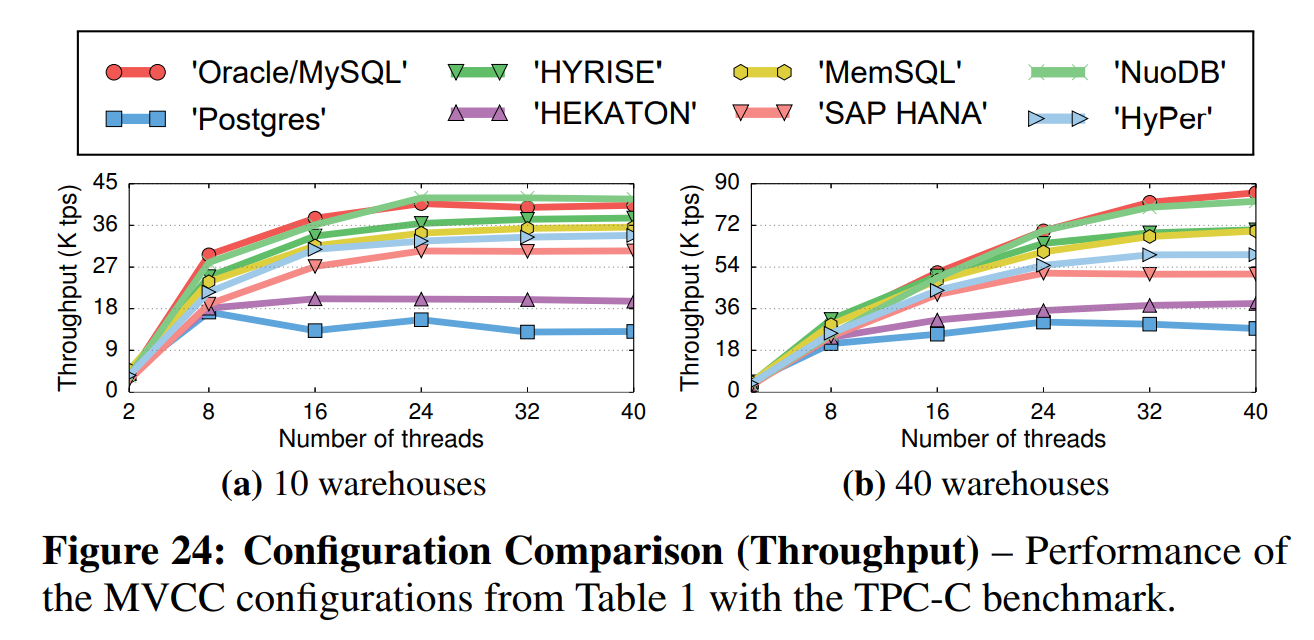
如图24所示,使用Oracle/MySQL和NuoBD的配置的DBMS在低争用和高争用负载下的表现都是最好的。这是因为这些系统的存储策略在多核和内存式系统中伸缩性最好,且它们的NV2PL协议无论在哪种争用的负载下都能提供相对高的性能。HYRISE、MemSQL和HyPer的配置的性能相对较低,因为它们使用的MVOCC协议在验证阶段需要的读取集合遍历会带来很高的开销。Postgres和Hekaton的配置的性能最差,其主要原因是它们使用的O2N顺序的仅追加存储严重限制了系统的可伸缩性。该实验表明并发控制协议和版本存储方案都可以对吞吐量产生很大影响。
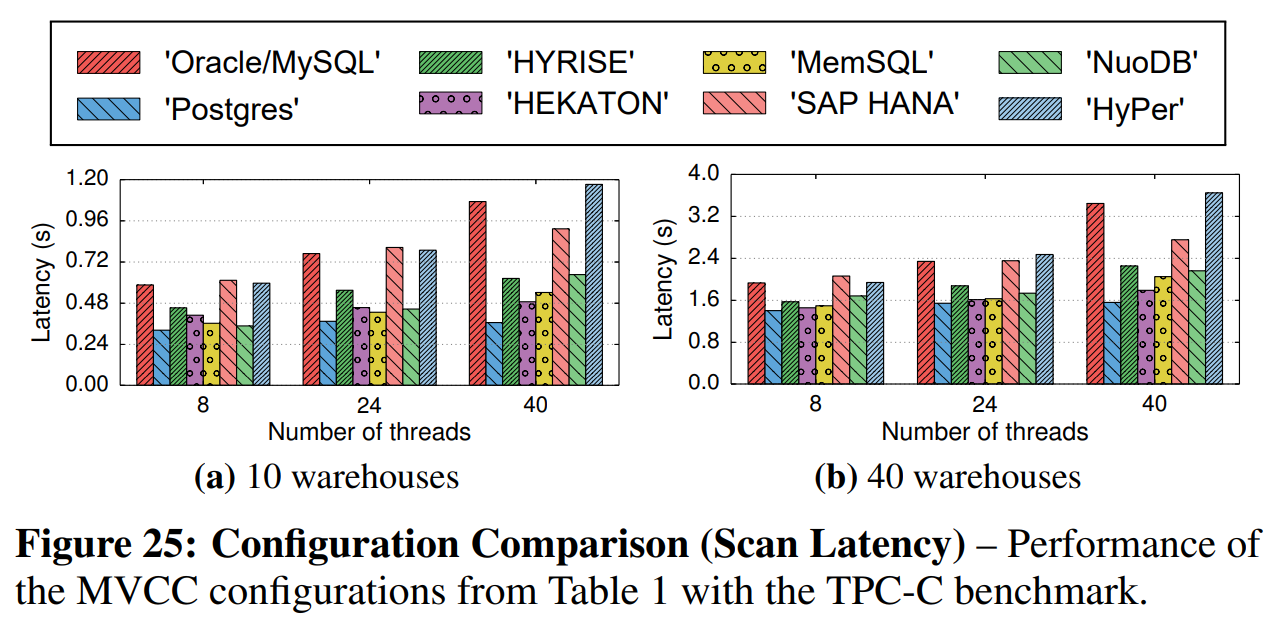
但是图25中的延迟结果显示,使用增量存储的DBMS性能最差。这是因为增量存储必须花费更多时间遍历版本链,以找到目标元组版本的属性。
9. 相关工作 #
最早提到MVCC的是1979年的Reed的论文[38]。在那之后,研究者专注于理论理解和MVCC在单核基于磁盘的DBMS中的性能[9, 11, 13]。我们着重介绍了时间更近一些的研究成果。
并发控制协议: 已有的一些工作提出了优化内存式事务处理的新技术[46, 47]。Larson等人[27]在Microsoft Hekaton DBMS的早期版本中比较了悲观协议(MV2PL)和乐观协议(MVOCC)[16]。Lomet等人[31]提出了一种使用时间戳范围解决事务间冲突的策略,Faleiro等人[18]等人分离了DBMS事务处理中的MVCC并发控制协议和版本管理。考虑到确保MVCC串行性的挑战,许多DBMS转而支持被称为快照隔离[8]的更弱的隔离级别,它不会排除写入倾斜异常(write-skew anomaly)。串行快照隔离(serializable snapshot isolation,SSI)通过消除快照隔离中可能发生的异常确保了串行性[12, 20]。Kim等人[24]使用SSN来在异构负载上扩展MVCC。我们在本文中的研究比它的范围更广。
版本存储: MVCC DBMS中的另一个重要的设计选择是版本存储策略。Herman等人[23]提出了一种不同的用于事务管理的结构,以在不妥协读取性能的同时实现高写入吞吐量。Neumann等人[36]通过本地事务存储优化减少了同步开销,提高了MVCC DBMS的性能。这些策略与传统的仅追加版本存储策略不同,传统的策略在内存为主的DBMS中有更高的内存分配开销。Arulraj等人[7]研究了在运行异构负载时,物理设计对混合DBMS性能的影响。
垃圾回收: 大多数DBMS都适用于元组级别的后台清理垃圾回收策略。Lee等人[29]评估了现代DBMS中使用的一系列不同的垃圾回收策略。他们提出了一种新的混合策略,减少了SAP HANA中的内存占用。Silo的基于epoch的内存管理方法让DBMS能够扩展到更多线程数量上[44]。这种方法仅在一个epoch(和之前的epoch)不再包含活动的事务后回收版本。
索引管理: 最新,有一些新的索引数据结构被提出,以支持可伸缩的内存为主的DBMS。Lomet等人[32]等人引入了一种无闩保序索引,称为Bw-Tree,目前在Microsoft的一些产品中使用。Leis等人[30]和Mao等人[34]分别提出了ART和Masstree,它们是基于Tries的可伸缩索引结构。本工作没有研究不同索引结构的性能,而是着眼于不同的辅助索引管理策略如何影响MVCC DBMS的性能。
10. 总结 #
我们发表了对内存式MVCC的事务管理设计决策的评估。我们描述了每种设计决策的最先进的实现,并展示了已有的系统是如何使用它们的。然后我们在Peloton DBMS中实现了它们,并使用OLTP负载来突出显示它们的权衡点。我们还展示了阻碍DBMS支持更多CPU核心数和更复杂的负载的问题。
致谢: This work was supported (in part) by the National Science Foundation (CCF-1438955) and the Samsung Fellowship Program. We also thank Tianzheng Wang for his feedback.
参考文献 #
[1] MemSQL. http://www.memsql.com.
[2] MySQL. http://www.mysql.com.
[3] NuoDB. http://www.nuodb.com.
[4] Oracle Timeline. http://oracle.com.edgesuite.net/timeline/oracle/.
[5] Peloton. http://pelotondb.org.
[6] PostgreSQL. http://www.postgresql.org.
[7] J. Arulraj and et al. Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads. SIGMOD, 2016.
[8] H. Berenson and et al. A Critique of ANSI SQL Isolation Levels. SIGMOD’95.
[9] P. A. Bernstein and N. Goodman. Concurrency Control in Distributed Database Systems. CSUR, 13(2), 1981.
[10] P. A. Bernstein, C. W. Reid, and S. Das. Hyder-A Transactional Record Manager for Shared Flash. In CIDR, 2011.
[11] P. A. Bernstein and et al. Concurrency Control and Recovery in Database Systems. 1987.
[12] M. J. Cahill, U. Röhm, and A. D. Fekete. Serializable Isolation for Snapshot Databases. SIGMOD, 2008.
[13] M. J. Carey and W. A. Muhanna. The Performance of Multiversion Concurrency Control Algorithms. TOCS, 4(4), 1986.
[14] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears. Benchmarking cloud serving systems with YCSB. In SoCC, 2010.
[15] T. David, R. Guerraoui, and V. Trigonakis. Everything You Always Wanted To Know About Synchronization But Were Afraid To Ask. In SOSP, 2013.
[16] C. Diaconu and et al. Hekaton: SQL Server’s Memory-Optimized OLTP Engine. SIGMOD, 2013.
[17] K. P. Eswaran and et al. The Notions of Consistency and Predicate Locks in a Database System. Communications of the ACM, 19(11), 1976.
[18] J. M. Faleiro and D. J. Abadi. Rethinking Serializable Multiversion Concurrency Control. VLDB, 2014.
[19] B. Fan, D. G. Andersen, and M. Kaminsky. MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing. In NSDI, 2013.
[20] A. Fekete, D. Liarokapis, E. O’Neil, P. O’Neil, and D. Shasha. Making Snapshot Isolation Serializable. TODS, 30(2), 2005.
[21] M. Grund, J. Krüger, H. Plattner, A. Zeier, P. Cudre-Mauroux, and S. Madden. HYRISE: A Main Memory Hybrid Storage Engine. VLDB, 2010.
[22] A. Harrison. InterBase’s Beginnings. http://www.firebirdsql.org/en/annharrison-s-reminiscences-on-interbase-s-beginnings/.
[23] S. Héman, M. Zukowski, N. J. Nes, L. Sidirourgos, and P. Boncz. Positional Update Handling in Column Stores. SIGMOD, 2010.
[24] K. Kim, T. Wang, J. Ryan, and I. Pandis. ERMIA: Fast Memory-Optimized Database System for Heterogeneous Workloads. SIGMOD, 2016.
[25] E. Klitzke. Why uber engineering switched from postgres to mysql. https://eng.uber.com/mysql-migration/, July 2016.
[26] H.-T. Kung and J. T. Robinson. On Optimistic Methods for Concurrency Control. TODS, 6(2), 1981.
[27] P.-Å. Larson and et al. High-Performance Concurrency Control Mechanisms for Main-Memory Databases. VLDB, 2011.
[28] J. Lee, M. Muehle, N. May, F. Faerber, V. Sikka, H. Plattner, J. Krueger, and M. Grund. High-Performance Transaction Processing in SAP HANA. IEEE Data Eng. Bull., 36(2), 2013.
[29] J. Lee and et al. Hybrid Garbage Collection for Multi-Version Concurrency Control in SAP HANA. SIGMOD, 2016.
[30] V. Leis, A. Kemper, and T. Neumann. The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases. ICDE, 2013.
[31] D. Lomet, A. Fekete, R. Wang, and P. Ward. Multi-Version Concurrency via Timestamp Range Conflict Management. ICDE, 2012.
[32] D. B. Lomet, S. Sengupta, and J. J. Levandoski. The Bw-Tree: A B-tree for New Hardware Platforms. ICDE, 2013.
[33] N. Malviya, A. Weisberg, S. Madden, and M. Stonebraker. Rethinking Main memory OLTP Recovery. ICDE, 2014.
[34] Y. Mao, E. Kohler, and R. T. Morris. Cache Craftiness for Fast Multicore Key-Value Storage. In EuroSys, 2012.
[35] C. Mohan. ARIES/KVL: A Key-Value Locking Method for Concurrency Control of Multiaction Transactions Operating on B-Tree Indexes. VLDB’90.
[36] T. Neumann, T. Mühlbauer, and A. Kemper. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. SIGMOD, 2015.
[37] A. Pavlo and M. Aslett. What’s Really New with NewSQL? SIGMOD Rec., 45(2):45–55, June 2016.
[38] D. P. Reed. Naming and Synchronization in a Decentralized Computer System. Ph.D. dissertation, 1978.
[39] D. P. Reed. Implementing Atomic Actions on Decentralized Data. TOCS, 1983.
[40] V. Sikka and et al. Efficient Transaction Processing in SAP HANA Database: The End of a Column Store Myth. SIGMOD, 2012.
[41] M. Stonebraker and L. A. Rowe. The Design of POSTGRES. SIGMOD, 1986.
[42] M. Stonebraker and et al. The End of an Architectural Era: (It’s Time for a Complete Rewrite). VLDB, 2007.
[43] The Transaction Processing Council. TPC-C Benchmark (Revision 5.9.0). http://www.tpc.org/tpcc/spec/tpcc_current.pdf, June 2007.
[44] S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden. Speedy Transactions in Multicore In-Memory Databases. In SOSP, 2013.
[45] T. Wang, R. Johnson, A. Fekete, and I. Pandis. Efficiently Making (Almost) Any Concurrency Control Mechanism Serializable. arXiv:1605.04292, 2016.
[46] Y. Wu, C.-Y. Chan, and K.-L. Tan. Transaction Healing: Scaling Optimistic Concurrency Control on Multicores. In SIGMOD, 2016.
[47] X. Yu, A. Pavlo, D. Sanchez, and S. Devadas. Tictoc: Time Traveling Optimistic Concurrency Control. In SIGMOD, 2016.
[48] X. Yu and et al. Staring Into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores. VLDB, 2014.
[49] W. Zheng, S. Tu, E. Kohler, and B. Liskov. Fast Databases with Fast Durability and Recovery Through Multicore Parallelism. In OSDI, 2014.