《Ceph: A Scalable, High-Performance Distributed File System》论文翻译

本篇文章是对论文weil-osdi06的原创翻译,转载请严格遵守CC BY-NC-SA协议。
作者
Sage A. Weil, Scott A. Brandt, Ethan L. Miller, Darrell D. E. Long, Carlos Maltzahn
University of California, Santa Cruz
{sage, scott, elm, darrell, carlosm}@cs.ucsc.edu
摘要
我们开发了分布式文件系统——Ceph,其能提供极好的性能、可靠性和伸缩性。Ceph使用为不可靠的对象存储设备(unreliable object storage devices,OSD)的异构动态集群设计的伪随机数据分布函数(pseudo-random data distribution function)CRUSH来替代分配表(allocation),从而最大化地分离了数据管理与元数据管理。我们通过数据副本、故障检测、和恢复的方式,将设备的智能译注1应用到运行专用本地对象文件系统的半自治OSD中。动态的分布式元数据集群提供了极为高效的元数据管理能力,并适用于大部分通用文件系统和科学计算文件系统的负载。从在各种负载下的性能测试中可以得出,Ceph有着极好的I/O性能和可伸缩的元数据管理能力,能够支持超过每秒25000次元数据操作。
译注1:这里的智能(intelligence)指OSD设备上的CPU与内存能够提供的能力,在后文中有提到。
1. 引言
系统长期以来一直在追求改进文件系统的性能,文件系统的性能已被证明对极多类型的应用程序的整体性能至关重要。科学计算和高性能计算社区推动了分布式存储系统在性能和伸缩性的提升,这比更通用的需求提前几年。如NFS[20]等传统解决方案提供了一个简单地模型,即服务器导出文件系统层次,客户端可将这个文件系统层次映射到它们的本地命名空间中。尽管这种方式被广泛使用,这种client/server模型中的中心化设计已被证明对可伸缩性的表现有很大阻碍。
更近一些的分布式存储系统采用了基于对象存储的架构,这种架构将传统的硬盘被替换为智能对象存储设备(OSD),OSD合并了CPU、网络接口、和有底层磁盘或RAID的本地缓存[4, 7, 8, 32, 35]。OSD用一个新的接口取代的传统的块级接口,客户端可以通过这个接口读写更大(且通常大小不一)的命名对象中的字节区间,并将低级块分配决策留给了设备本身。客户端通常与以元数据服务器(metadata server,MDS)交互的方式来执行元数据操作(如open、rename),而直接与OSD通信来以执行文件I/O(read、write),这大改善了整体的可伸缩性。
采用这种模型的系统由于很少或没有分发元数据的负载,其还是会受可伸缩性限制的困扰。而继续依赖传统文件系统的原则(如分配列表和inode列表)且不愿将智能委托给OSD进一步限制了可伸缩性和性能,且增加了可靠性的开销。
因此,我们提出了Ceph,Ceph是一个提供了极好的性能与可靠性且具有无可比拟的可伸缩性的分布式文件系统。我们的架构基于如下的假设:PB级别的系统本质上是动态的————大型系统不可避免的需要增量构建、节点故障是常态而不是意外、负载的量和特征会随着时间不断改变。
Ceph通过使用生成函数来替代文件分配表的方式,将数据操作与元数据操作解耦。这让Ceph能够利用OSD已有的智能来分散数据访问、串行更新、副本与可靠性、故障检测和恢复的复杂性。Ceph采用了高适用能力的分布式元数据集群架构,这极大地提高了元数据访问的可伸缩性,并因此提高了整个系统的可伸缩性。我们将讨论那些驱动我们选择了这种架构的目标与负载假设、分析它们对系统可伸缩性和性能的影响、并与我们在实现功能性系统原型的经验相结合。
2. 系统总览
Ceph文件系统有3个主要部件:(1)客户端:为主机或进程暴露类POSIX文件系统接口的实例;(2)OSD集群:共同存储所有的数据与元数据;(3)元数据服务器集群:管理命名空间(文件名与目录),同时协调安全性(security)、一致性(consistency)和连贯性(coherence)。如图1所示。我们称Ceph接口是类POSIX接口,因为我们为了更好地与应用程序的需求对齐并改进系统性能,我们对POSIX接口进行了适当的扩展,并选择性地放松了一致性语义。
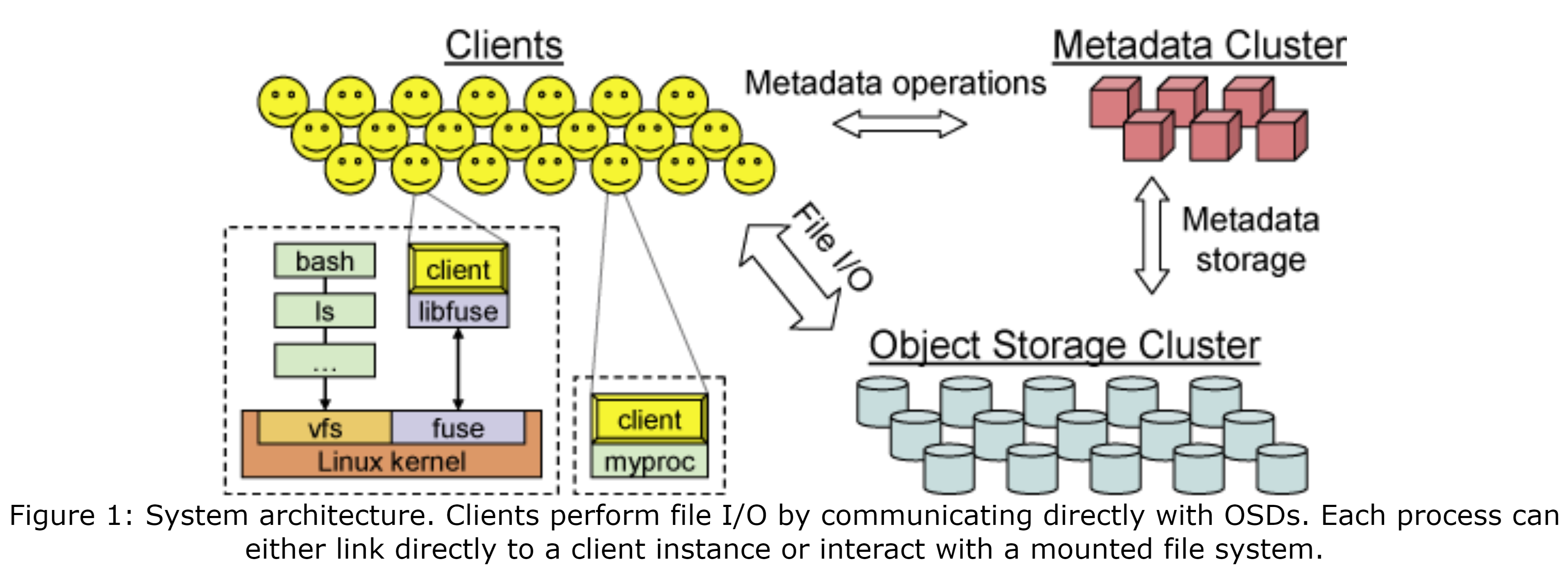
该架构的主要目标是伸缩性(用于数百PB或更多)、性能、和可靠性。伸缩性被从多维度考虑,包括系统整体的存储容量、吞吐量、和单个客户端、目录或文件的性能。我们的目标负载可能包括一些极端情况,如数万或数十万个主机并发地读取或写入同一个文件,或在同目录下创建文件。这种场景在运行在超级计算机集群上的科学计算程序中很常见,并在未来的通用的负载中越来越多地起着指示作用。更重要的是,我们发现分布式文件系统的负载本质上是动态的,随着活动的应用程序和数据集随着时间的变化,数据与元数据的访问也显著的变化。Ceph直接解决了伸缩性的问题,同时通过三个基本设计特性解决了高性能、可靠性和可用性,这三种设计为:数据与元数据解耦、动态分布式元数据管理、和可靠的自主分布式对象存储。
数据与元数据解耦: Ceph将文件元数据与管理与文件数据的存储最大化地进行了分离。元数据操作(如open、rename等)被元数据集群共同管理,同时,客户端直接与OSD交互来执行文件I/O(读取和写入)。基于对象的存储通过将低级的块分配决策交给单个设备以提高文件系统的可伸缩性。然而,与现有的基于对象的文件系统[4, 7, 8, 32]不同,Ceph使用更短的对象列表替代较长的每个文件的块列表,因此完全消除了分配列表。文件数据被分条(strip)为可预测的命名对象上,同时通过一个叫CRUSH[29]的专用数据分布函数将对象分配到存储设备上。这让任一方都可以计算(而不是查找)组成文件内容的对象的名称与位置,消除了维护与分发对象列表的需求,简化了系统设计,减少了元数据集群的负载。
动态分布式元数据管理: 因为文件系统元数据操作组成了传统文件系统负载的一半[22],高效的元数据管理对整个系统的性能非常重要。Ceph使用了一种基于动态子树分区(Dynamic Subtree Partitioning)[30]的新式元数据集群架构,并智能地将管理文件系统目录层级的责任分布到数十甚至数百个MDS上。(动态的)分层分区在每个MDS的负载都保持了局部性,这促进了高效地更新和主动式预取来改进常见的负载的性能。重要的是,元数据服务器间的负载分布完全基于当前的访问模式,使Ceph在任何负载下都能够高效利用可用的DMS资源,并实现与MDS数量呈近线性的伸缩性。
可靠的自主分布式对象存储: 由成千上万个设备组成了大型系统本质上是动态的:它们是被增量构建的,当部署新存储或退役旧设备时,它们会跟着伸展或收缩,且大量的数据会被创建、移动、和删除。所有的这些因素都要求数据的分布变得能够高效利用可用资源并维护所需的数据副本等级。Ceph把数据迁移、复制、故障检测、和故障恢复的责任托付给了存储数据的OSD集群,同时在上层,OSD共同为客户端和元数据服务器提供一个逻辑对象存储。这种方法让Ceph能够更高效地利用每个OSD的智能(CPU和内存)来实现可靠的、高可用的、有着线性伸缩性的对象存储。
本文中,我们描述了Ceph的客户端的操作、元数据服务器集群、和分布式对象存储,还描述了我们的架构怎样影响它们的关键特性。我们还描述了我们原型的状态。
3. 客户端操作
我们将介绍Ceph组件的整体操作,并通过描述Ceph的客户端的操作的方式介绍它们与应用程序的交互。Ceph的客户端运行在每个执行应用程序代码的主机上,并为应用程序暴露文件系统接口。在Ceph原型中,完全运行在用户空间,且既可以直接链接到它来访问,又可以通过FUSE(一种用户空间文件系统接口)[25]作为挂载的文件系统访问。每个客户端维护它拥有的文件数据缓存,该缓存与内核也或缓冲区缓存独立,使直接链接了客户端的应用程序能够访问它。
3.1 文件I/O和功能
当进程打开一个文件时,客户端会向MDS集群发送一个请求。MSD会遍历文件系统的层次结构,将文件名转换为文件的inode,inode中包括唯一的inode编号、文件所有者、模式、大小、和其他的单文件元数据。如果文件存在并有访问权限,MDS会返回inode编号、文件大小和将文件数据映射到对象的分条策略的信息。MDS可能还会向客户端发送(如果其还没收到过)指定了哪些操作是被允许的功能(capability)信息。目前,这些功能包括4位,其控制客户端的读(read)、缓存读(cache reads)、写(write)、和缓冲写(buffer writes)的能力。在未来,其功能还将包括允许客户端向OSD证明其被授权了读写数据权限的安全密钥[13, 19](目前,原型信任所有客户端)。后续操作中,MDS在文件I/O中的参与仅限于管理功能,以维护文件的一致性并实现适当的语义。
Ceph有很多将文件数据映射到一系列对象上的分条策略。为了避免任何对与新文件分配(allocation)相关元数据的需求,对象名简单地将文件inode编号和条带(stripe)号。接着,会使用CRUSH将对象的副本分配到OSD上,CRUSH是全局可知的映射函数(在章节5.1中介绍)。例如,如果一个或多个客户端打开了一个文件用来读取,MDS会为它们授权读取和缓存文件内容的功能。有了inode编号、布局、和文件大小,客户端可以命名并定位所有包含文件数据的对象,并能够直接从OSD集群读取。任何不存在的对象或字节区间被定义为文件的“洞”,或者“零值”。类似地,如果客户端打开了文件用来写入,它会被授权带缓存的写入的功能,其在该文件的任何偏移量上生成的任何数据会被简单地写入到适当OSD上的适当对象中。客户端在文件关闭时会放弃(relinquish)对应的功能,并向MDS提供新文件的大小(写入的最大偏移量),这会重新定义(可能)已有的包含文件数据的一系列对象。
3.2 客户端同步
POSIX要求读取操作能够反映之前写入的任何数据,且写入操作时原子性的(也就是说,重叠的并发写入将会反映一个特定的写入顺序)。当文件被多个客户端打开时(多个writer或既有writer又有reader),MDS将会收回之前任何的缓存读取和缓冲区写入功能,强制同步客户端对该文件I/O。这样,每个应用程序的读取或写入操作将会被阻塞,直到OSD确认,这增加了OSD中存储的每个对象的串行更新和同步的负担。当写入跨对象边界时,客户端会请求对受影响的对象的独占锁(由这些对象所在的各自OSD授权),并立即提交写入并解锁操作,以实现所需的串行性。对象锁还可被用于在大型写入时,通过获取锁并异步冲刷(flush)数据来掩盖延迟。
意料中的是,同步I/O对应用程序的性能有很大的影响,特别是对那些进行少量读写的应用程序来说更加明显,这时延迟造成的,其至少需要与OSD的一次往返的延迟。尽管在通用的负载中,读写共享的情况相对比较少[22],但是在可写计算应用程序中,这种场景是非常常见的[22],且这种情况下性能通常很重要。因此,当应用程序不需要依赖严格的标准一致性时,通常希望能够放松一致性来减少开销。尽管Ceph支持通过全局的开关来放松一致性,正如许多其他分布式文件系统在该问题上做的一样[20],但是这是一种不精确且不能令人满意的觉接方案:要么性能会下降,要么会在系统范围下丢失一致性。
正由于这个原因,高性能计算(high-performance computing,HPC)社区[31]提出了一系列的对POSIX I/O的高性能计算扩展接口,Ceph中实现了这些接口中的一个子集。其中最引人注意的是,open操作的O_LAZY标识符允许应用程序显式地放松对共享写文件通常的连贯性要求。管理自己连贯性(例如HPC负载中常见的模式,通过写入同一个文件的不同部分)的性能敏感型程序在执行I/O时就可以通过缓冲区写入或通过缓存读取,否则只能同步执行。如果需要,应用程序可以进一步显式地通过两种额外的调用进行同步:lazyio_propagate会将给定的字节区间冲刷到对象存储中、lazyio_synchronize会确保过去的修改会在任何后续的读取中反映。因此,为了保持Ceph同步模型的简单性,其在客户端间通过同步I/O提供正确的读-写和共享写语义,并扩展了应用程序接口来放松性能敏感的分布式程序的一致性。
3.3 命名空间操作
客户端与文件系统命名空间的交互由元数据服务器集群管理。读操作(如readdir、stat)和更新(如unlink、chmod)都由MDS同步应用,以确保串行、一致性、正确的百密性(correct security)、和安全性(safety)。为了简单起见,客户端不使用元数据锁或租约。特别是对于HPC的负载,回调能够提供好处很小,但复杂性的潜在开销很高。
相反,Ceph为大多数通用元数据访问场景做了优化。在readdir之后对每个文件执行stat(例如,ls -l)是一个非常常见的访问模式,且是在大目录下臭名昭著的性能杀手。Ceph中的readdir仅需一次MDS请求,它会拉取整个目录。包括inode的内容。默认情况下,如果readdir后面会立刻接一个或多个stat,那么被缓存的简短的信息会被返回;否则,缓存的信息就被丢弃。虽然这种方法在中间inode修改可能不会被注意到的情况下稍稍放松了连贯性,但是我们还是十分乐于通过这种交换来大幅改进性能。这种行为可被readdirplus[31]扩展显式地捕捉到,它会返回整个目录的lstat的结果(正如再一些专用OS的实现中getdir已经做的那样)。
Ceph可以通过更久地缓存元数据来允许一致性被进一步放松,这很像早期版本的NFS做的那样,其通常缓存30秒。然而,这种方法会在某种程度上打破连贯性,通常这对应用程序来说是很重要的,比如那些使用stat来判断一个文件是否被更新过的应用程序。如果这样做,这些应用程序可能会执行不正确的行为,或要等待旧的缓存值超时。
我们再次选择了提供正确的行为并扩展了对性能有不利影响的接口。这种选择可通过下例清楚的说明:对一个被多个客户端并发为写入而打开的文件的stat操作。为了返回正确的文件大小和修改时间,MDS会收回任何写入的功能,以立刻停止更新并采集最新的大小和所有writer的修改时间。其中最大值会被返回,随后被撤销的功能会被重新下发以执行后续进程。尽管停止多个writer似乎有些过于激进,但为了保证合理的串行化,这时必需的。(对于单个writer,可以从正在写入的客户端检索到正确值,而不需要打断进程。)不需要连贯性行为的应用程序(也就是需求与POSIX接口不一致的受害者)可以使用statlite[31],其通过一个位掩码来执行哪些inode字段不需要连贯性。
4. 动态分布式元数据
元数据操作经常会占用文件系统一半的负载[22]且操作位于关键路径中,这对MDS集群的整体性能来说是至关紧要的。元数据管理也成为了分布式文件系统中伸缩性的重要挑战:尽管在增加更多存储设备时,容量和总I/O速率几乎可以任意伸缩,但是元数据操作设计更大程度的相互依赖关系,这使可伸缩的一致性与连贯性管理变得更加困难。
Cpeh中的文件和目录的元数据非常小,其由几乎整个目录里的条目(文件名)和inode(80B)组成。不像传统的文件系统,Ceph中没有文件分配(allocation)元数据是必要的——对象名由inode号组成,并通过CRUSH分布到OSD中。这简化了元数据负载并使我们的MDS能够高效的管理大量的文件,无论文件有多大。我们的设计通过双层存储策略(two-tiered storage strategy)进一步追求减少元数据相关的磁盘I/O,并最大化局部性(locality),且通过动态子树分区(Dynamic Subtree Partitioning)[30]来高效利用缓存。
4.1 元数据存储
尽管MDS集群的目标是通过其内存缓存来满足大部分请求,但是为了安全起见,元数据的更新必须被提交到磁盘上。一系列大量、有界、懒惰冲刷的日志(journal)让每个MDS可以高效、分布式地将其更新的元数据流式写入到OSD集群中。每个MDS的几百MB的日志中也会有重复的元数据更新(在大多数负载中很常见),因此当旧的入职条目最终被冲刷到长期存储时,许多条目已经被废弃了。尽管MDS的恢复目前还没在我们的原型中实现,日志还是按照如下功能设计的:当一台MDS故障时,另一台节点可以快速重新扫描日志并恢复故障节点内存缓存中的重要内容,以恢复文件系统的状态。
这种策略是两全其美的:可以高效(顺序)地流式更新到磁盘,且大大较少了重写的负载,这允许长期磁盘存储的布局可对未来的读访问进行优化。特别是,inode被直接嵌入到了目录中,这让MDS可以通过单词OSD读请求预拉取整个目录,并高度利用大部分负载中的目录局部性[22]。每个目录的内容会使用与元数据日志和文件数据相同的分条和分布策略写入OSD集群中。inode编号会按照一定范围分配给元数据服务器,且在我们的原型中inode编号被认为是不可变的,尽管之后在文件删除时它们可能会被简单地回收。辅助锚表(auxiliary anchor table)用来保存很少见的有多个硬链接的可通过编号全局寻址的inode,所有这些都不需要使用非常常见的有庞大、稀疏且笨重的inode表的单链接文件。
4.2 动态子树分区
我们的主拷贝缓存策略(primary-copy caching strategy)让一个权威的MDS负责管理对任意给定元数据片段的缓存一致性和串行更新。大部分现有的分布式文件系统使用某种基于子树的静态分区的形式来授权(通常强迫管理员将数据集分割为更小的静态“卷”),一些最近的实验性文件系统使用了哈希函数来分布目录和文件元数据[4],这为分摊负载而牺牲了局部性。这两种方法都有严重的局限性:静态子树分区无法应对动态的负载和数据集,而哈希破坏了元数据的局部性和实现高效元数据预拉取与存储的重要的可能性。
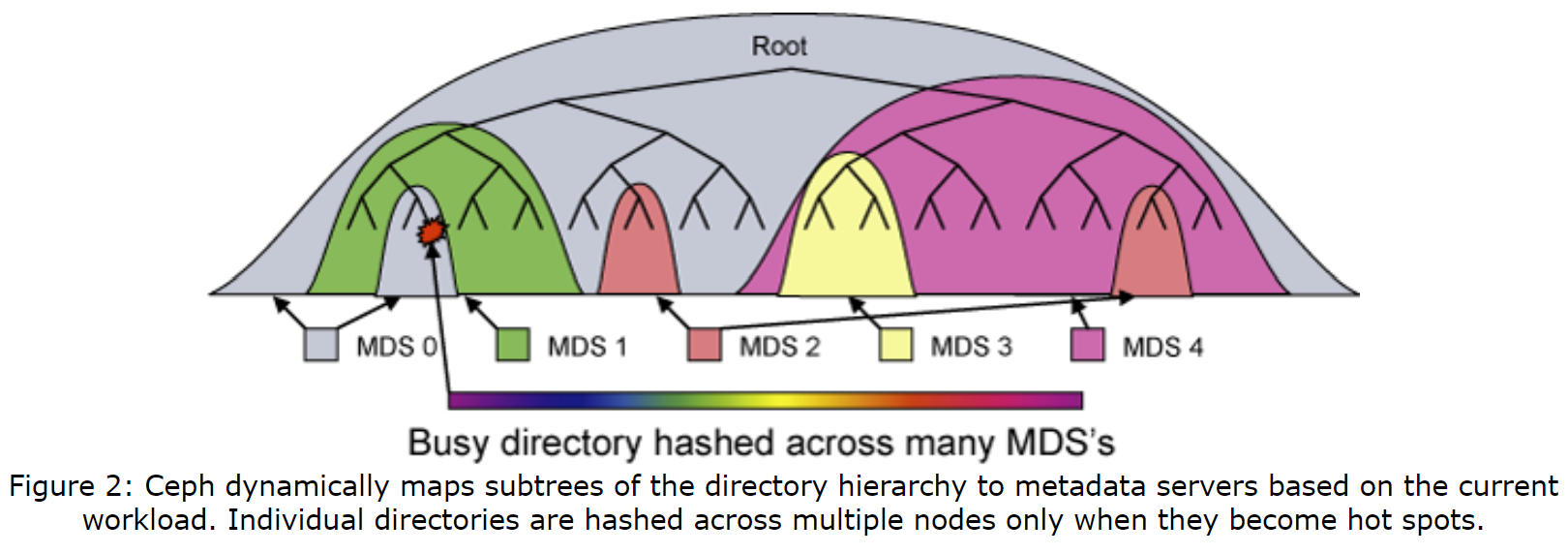
Ceph的MDS集群基于一种动态子树分区策略[30],其在一组节点间自适应地分层分布缓存元数据,如图2所示。每个MDS会通过随时间指数衰减的计数器来测量每个目录层级的元数据的流行度(popularity)。任何操作都会增长受影响的inode和从它们开始向上直到根目录所有计数器,这为每个MDS提供了描述最近负载分布的加权树。每个一段时间,MDS的负载值会被进行比较,且目录层级的适当大小的子树会被迁移,以保证负载最终会被分布。使用共享的长期存储和谨慎构造的命名空间锁,让这种迁移可以通过将内存缓存中的适当的内容传输到新的被授权的节点实现,这样可以减少对连贯性锁或客户端功能的影响。为了安全起见,导入的元数据会被写入新MDS的日志中,且两边的额外日志确保了授权的转移不会受中间发生的故障影响(类似于两段式提交)。最终得到的基于子树的分区会保持粗粒度,以减少前缀复制开销并保持局部性。
当元数据被复制到多个MDS节点时,inode的内容会被划分为三组,每组都有不同的一致性语义:安全组(所有者、模式)、文件组(大小、修改时间)、和不可变组(inode编号、创建时间、布局)。不可变组的字段永远不会改变,而安全组合文件组会被单独的有限状态机管理,每个有限状态机都有不同的一系列状态和转移,这样的设计是为了在减少锁的争用的同时适应不同的访问和更新模式。例如,在路径遍历时,会需要对“所有者”和“模式”进行安全检查,但二者很少变化,仅需很少的状态;而因文件锁控制MDS发送给客户端的功能,其反映了更广的客户端访问模式,
4.3 流量控制
将目录层级在多台节点上分区可以均衡负载,但是不是总能解决热点(hot sopt)和瞬时拥堵(flash crowd)问题,在这些问题中,许多客户端会访问同一个目录或文件。Ceph通过它对元数据流行度的了解,将热点宽泛地分布,这仅在需要时执行,且一般情况下不会曹正相关的额外开销和目录局部性的损失。被大量读取的目录(例如被多个open打开)的内容会被有选择地在多个节点上备份以分布负载。特别大或者有大量写入负载的目录(如目录有许多文件的创建)的内容会按文件名哈希并分布在集群中,以牺牲目录的局部性来换取负载的平衡。这种自适应的方法让Ceph适用于各种分区粒度,让文件系统在特定环境下的不同部分能够有最有效的分区粒度策略,让系统能同时获得粗粒度和细粒度带来的好处。
每个MDS的响应都为客户端提供了有关授权和相关inode和其任何副本及祖先inode的更新后的信息,让客户端了解文件系统中与客户端交互的部分的元数据分区。之后的元数据操作将会基于给定路径中已知的最深前缀,直接与被授权的结点进行(对于更新操作),或者与随机一份副本进行(对于读取操作)。通常,客户端会得知不流行(没被做副本的)的元数据的位置,且可以直接与适当的MDS通信。而对于访问流行元数据的客户端,它们会被告知元数据贮存在不同的或多个MDS节点上,这可以有效限制认为元数据中任一部分贮存在任一MDS上的客户端的数量,这样可以在潜在的热点和瞬时拥堵产生前分散负载。
5. 分布式对象存储
从上层来看,Ceph的客户端和元数据服务器视对象存储集群(可能有上万或上十万个OSD)为一个对象存储和命名空间。Ceph的可靠自主分布式对象存储(Reliable Autonomic Distributed Object Store,RADOS)在容量和整体性能方面实现了线性伸缩性,这是通过将对象备份、集群扩展、故障检测和恢复等方面的管理分布式地授权给OSD实现的。
5.1 使用CRUSH分布数据
Cpeh必须将PB级的数据分布到由数千个存储设备组成的不断演进的集群上,这样可以有效地利用设备存储和带宽资源。为了避免不平衡(例如,最近部署的设备几乎是空闲或空的)或负载不对称(例如,新的、热点的数据仅在新设备上),我们使用了这样一种策略:随机分布新数据、对已有数据随机二次抽样并迁移到新设备、均匀地重分配被移除的设备中的数据。这种随机的方法具有鲁棒性,其可以在任何潜在的负载中有同样好的表现。
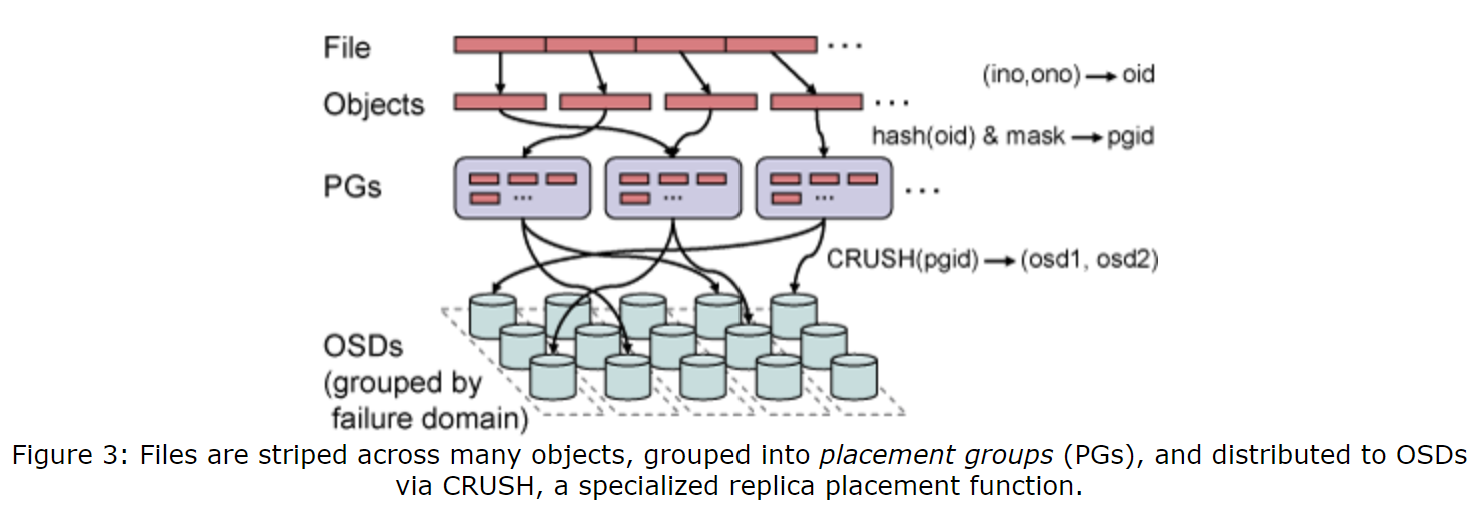
Ceph首先使用一个简单的哈希函数将对象映射到放置组(placement group,PG)中,该哈希函数中有一个可调的位掩码,以控制PG的数量。我们选定的值给每个OSD大约100个PG,来通过平衡每个OSD维护的副本相关的元数据的总量,以平衡OSD利用率的差异。接着,会将放置组通过CRUSH算法(Controlled Replication Under Scalable Hashing)分配给OSD,CRUSH是一个伪随机数据分配函数,其可以高效地将每个PG映射到一个有序的存储对象副本的OSD列表上。这与传统的方法(包括其他的基于对象的文件系统)的不同之处在于,数据分配不依赖任何块或对象列表元数据。为了定位任意对象,CRUSH仅需要放置组和OSD集群映射,二者是对组成存储集群的设备的紧凑、分层的描述。这种方法有两个关键优势:首先,这是完全分布式的,任何一方(客户端、OSD或MDS)可以独立地计算任何对象的位置;第二,映射不会频繁更新,这消除了任何与数据分布相关的元数据交换。这样做,CRUSH同时解决了数据分布问题(“我该把数据存在哪儿”)和数据定位问题(“我把数据存到哪儿了”)。按照设计,对存储集群的较小的修改对已有的PG映射影响非常小,这减少了由于设备故障或集群扩展而导致的数据迁移。
集群映射的结构层次被构造为与集群的物理或逻辑组成和潜在的故障源保持一致。例如,用户可以为一个由满是OSD的机架格(shelf)、满是机架格的机架(rack cabinet)、和多行机架(row of cabinet)组成的设备构造一个4层的映射。每个OSD还有一个权值,用来控制分配给它的相对的数据总量。CRUSH会基于放置规则(placement rule)把PG映射到OSD,放置规则定义了副本级别和任何放置上的约束。例如,用户可能想把每个PG在3个OSD上做副本,且所有副本都在同一行机架(以限制机架行间的备份流量)但位于不同的机架上(以减少电源电路或边缘开关故障带来的影响)。集群映射还包括一个离线或非活跃设备的列表和一个时期号(epoch number),每次映射变化时该时期号会增加。所有OSD请求会被打上客户端映射的时期号的标签,这样,所有方会对当前的数据分布达成一致。增量的映射更新会在协作的OSD间共享,如果映射更新,OSD的回复中也会带上这个数据。
5.2 副本
与像Lustre[4]这样的系统不同,Lustre假设用户可以在SAN上使用RAID或故障转移机制(fail-over)来构建足够可靠的OSD,而我们假设PB或EB的系统中故障是正常时间而非异常事件,且在任意时间点都会有几个OSD可能无法使用。为了维护系统的可用性并在系统伸缩时仍能保证数据安全,RADOS使用一种主拷贝备份(primary-copy replication)的变体[2]来管理其自己的数据副本,同时采取措施以减少对性能的影响。
数据被按照放置组备份,每个放置组被映射到一个由n个OSD组成的有序列表上(为了n路备份)。客户端将所有的写请求发送到对象的PG中第一个没有故障的OSD中(主OSD,primary OSD),其会为该对象和PG分配一个新的版本号,并将写请求进一步传递给所有其他的备OSD(replica OSD)上。在每个副本都应用了更新并响应主OSD后,主OSD会将更新应用到本地并通知客户端这次写入。读请求会被定向到主OSD。这种方法为客户端省去了副本间同步或串行所带来的复杂性,在有其他writer或故障恢复时,这会变得很麻烦。这种方法还会将做副本消耗的带宽从客户端转移到OSD集群内部网络中,在我们的期望中,OSD集群内部网络会有更多的可用资源。中间的备OSD故障会被胡烈,因为任何的后续恢复操作(章节5.5)都将可靠地恢复副本的一致性。
5.3 数据安全性
在分布式存储系统中,数据被写入共享存储的关键原因有两个。首先,客户端希望它们的更新对其他客户端可见。这一过程应该完成得很快:写入尽可能快地可见,特别是多writer既有reader又有writer的情况下,需要强制客户端同步操作。第二,客户端希望确切地知道它们写入的数据是否被安全地在磁盘上备份、数据是否可以在断点或其他故障时幸存。RADOS在得知更新时,会将同步与安全性分离,让Ceph能够实现高效应用程序同步中的低延迟,与良好定义的数据安全性语义。
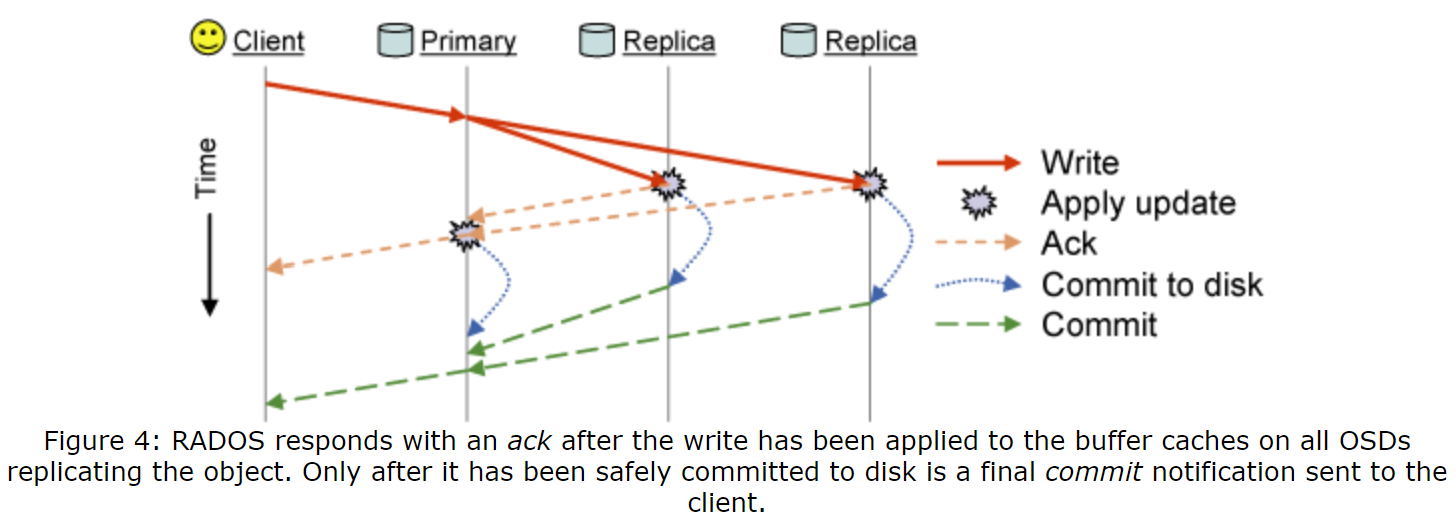
图4阐述了在对象写入时发生的消息发送。主OSD将更新进一步传递给备OSD,并在更新被应用到所有OSD的内存缓冲区缓存后回复一个ack,让客户端的同步POSIX返回。当数据被安全地提交到磁盘时,会发送一个最终的commit(可能在数秒后)。我们仅在更新被完全被分到所有无缝容错的单个OSD后才会发送ack,尽管这回增加客户端的延迟。默认情况下,客户端还会缓冲写入请求,直到它们提交,以避免放置组中所有OSD同时断点时发生数据丢失。在这种情况下恢复时,RADOS允许在接受新的更新之前,在固定的时间内重放(replay)之前已知的(有序的)更新。
5.4 故障检测
及时的故障检测对维护数据安全是非常重要的,但是当集群扩展到几千台设备时,这会变得很困难。对于特定的故障,如磁盘错误或数据损坏,OSD可以自己报告。而对于使OSD网络不可用的故障,则需要主动监控,RADOS通过让每个OSD监控与其共享PG的对等节点(peer)来分配监控任务。在大多数情况下,已有的副本的流量会被用作被动的存活确认,而不需要额外的通信开销。如果OSD最近没有收到对登记诶单的消息,那么会显式地发送一个ping。
RADOS会送两个维度考察OSD的存活性:OSD是否可以访问、其是否被CRUSH分配了数据。没有相应的OSD最初会被标记为down状态,任何的主要职责(更新、串行化、副本)会被临时地传递给其PG中的下一个OSD。日过OSD没有快速恢复,其会被在数据分布中标记为out,另一个加入每个PG的OSD会重新复制其中的内容。而向故障OSD执行挂起操作的客户端只需要简单地重新提交到新的主OSD即可。
因为各种网络异常都可能导致OSD的网络间歇性中断,所以我们使用一个小的监控集群采集故障报告,并集中过滤出瞬时的或系统的问题(如网络分区)。监控者(仅被部分实现)采用选举、主动对等节点监控、短期租约、和两段式提交的方式共同提供对集群映射的一致且可用的访问。当映射更新并反映出任何故障或恢复时,会向受影响的OSD提供增量的映射更新,然后利用现有的OSD间的通信将更新扩散到整个集群中。分布式的检测可以在不过量增加监控负担的同时实现快速的检测,通知还可以解决集中式仲裁而导致的不一致。最重要的是,RADOS通过将OSD标记为down而不是out的方式,避免了因系统问题导致的大范围的数据重做副本的问题(例如断电后半数OSD挂掉)。
5.5 恢复和集群更新
OSD集群会因OSD故障、恢复和显式的集群修改(如部署新存储)而改变。Ceph用相同的方式处理所有的这种改变。为了实现快速恢复,OSD为每个对象维护一个版本号并为每个PG维护一个最近改变(更新或删除的对象名和版本号)的日志(类似于Harp[14]中地副本日志)。
当一个活动的OSD收到了一份集群映射更新时,它会遍历本地存储的PG并计算CRUSH映射来决定它作为主OSD或备OSD负责哪些PG。如果OSD是PG的备OSD,OSD会向主提供其PG当前的版本号。如果OSD是PG的主OSD,岂会采集当前(和之前的)备OSD的PG版本号。如果主OSD缺少大部分的PG的最近状态,它会重新计算来自PG当前或之前的OSD中的最近PG修改的日志(或者如果需要的话,会完整地执行计算),以决定正确的(最近的)PG内容。主OSD随后向每个备OSD发送增量的日志更新(或者如果需要的话,发送完整的内容),这样所有方都会知道PG的内容应该是什么,即使这与它们本地存储的对象可能不匹配。仅在主OSD决定了正确PG的状态并将其分享给其他所有备OSD后,才允许对对象进行I/O。然后,OSD就会独立负责根据它们的对等节点计算丢失或过失的对象。如果OSD收到对过时或丢失的对象的请求,它会推迟处理,并将这个对象移到恢复队列的前端。
例如,假设osd1故障并被标记为down,那么osd2会接管pgA并作为其主OSD。如果osd1恢复,其会在启动时请求最近的映射,且一个监控者会将其标记为up。当osd2收到导致映射变化的更新时,它会意识到其不再是pgA的主OSD,并将pgA的版本号发送给osd1。osd1将会重新计算来自osd2的pgA的日志条目,告知osd2其内容是最新的,并随后当任何更新的对象在后台恢复完成时开始处理对应的请求。
因为故障恢复完全由OSD独立驱动,每个被故障OSD影响的PG会(很可能地)在不同的放置的OSD中并行地恢复。这种基于快速恢复机制(Fast Recovery Mechanism,FaRM)的方法,减少了恢复时间并提改进了整体数据安全性。
5.6 使用EBOFS的对象存储
尽管很多的分布式文件系统使用像ext3的本地文件系统来管理下层存储[4, 12],我们发现它们的接口和性能都不适合对象的负载[27]。已有的内核接口限制了我们了解对象的更新在何时被安全地提交到磁盘上的能力。同步的写入或者日志提供了我们需要的安全性,但是会带来严重的延迟和性能的损失。最重要的是,POSIX接口无法支持原子性数据和元数据(如属性)更新事务,这对维护RADOS的一致性是非常重要的。
因此,Ceph的每个OSD通过EBOFS管理其本地对象存储,EBOFS是一个基于区段B树(Extent and B-Tree)的文件系统。EBOFS的实现完全在用户空间中,且直接与原始块设备交互,这让我们能够定义我们自己的下层对象存储接口并更新语义,这将更新串行化(为了同步)与磁盘提交(为了安全性)分离开来。EBOSF支持原子事务(如对多个对象的写入和属性更新),且更新函数在内存缓存更新时返回,同时提供了异步的提交通知。
使用用户空间的方法,除了提供了更好的灵活性且更容易实现外,还避免了与Linux VFS和也缓存的笨重的交互,这二者是为不同的接口和负载设计的。大部分的内核文件系统在一定时间后懒式地将更新冲刷到磁盘,而EBOFS主动的调度磁盘写入,并在I/O操作等待中且后续的更新导致磁盘写入变得不必要时,EBOFS会取消它这次写入。这让我们的下层磁盘调度器有更长的I/O队列,且相应的调度效率会提高。用户空间调度器还可以更简单地对负载按优先级排序(例如,客户端I/O vs 恢复)或提供服务质量保证[36]。
EBOFS的设计核心是一个鲁棒性的、灵活地、完全集成了B树的服务,其被用作在磁盘上定位对象、管理块分配、和索引采集(PG)。块分配按照区间起点和长度的对管理的,而不采用块列表,以保持元数据紧凑。磁盘上的空闲块区间按照大小和位置分类,使EBOFS能够在磁盘上快速定位写入位置附近的空闲空间或相关数据,同时限制了长碎片的量。为了性能和简单起见,除了每个对象的块分配信息外,所有的元数据都被保存在内存中(即使对容量很大的文件系统来说,这些信息也非常小)。最后,EBOFS积极地使用写入时复制(copy-on-write):除了超级块(superblock)更新外,数据总是被写入到未分配的磁盘区域。
6. 性能与可伸缩性评估
我们通过一系列的微批量的benchmark来评估我们的原型以展示其性能、可靠性、和可伸缩性。在所有的测试中,客户端、OSD、和MSD都是用户进程,运行在双处理器、SCSI磁盘、并通过TCP通信的Linux集群上。通常,每个OSD或MDS运行在其自己的主机上,而在生成负载时,数十或数百个客户端可能共享同一个主机。
6.1 数据性能
EBOFS提供了优秀的性能和安全性语义,同时,CRUSH生成的数据的均衡分布和副本与故障恢复的委托机制让整体的I/O性能随OSD集群的大小伸缩。
6.1.1 OSD吞吐量
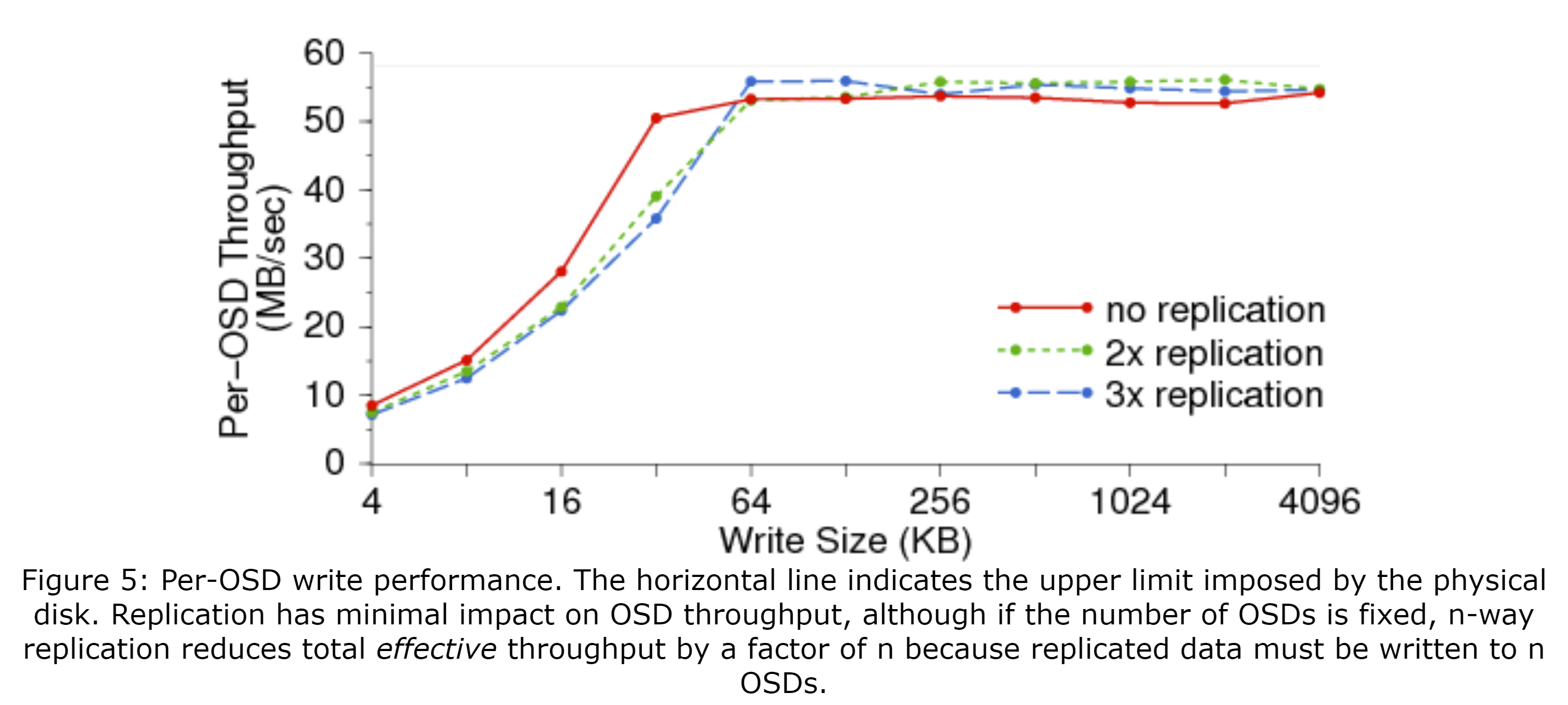
我们从测量14个OSD节点组成的集群的I/O性能开始。图5展示了在不同的写入大小(x轴)和副本数下每个OSD的吞吐量(y轴)。负载由20个额外节点的400个客户端生成。如图中的水平线所示,性能基本上受限于原始磁盘带宽(约58MB/s)。副本让磁盘I/O翻了两倍或三倍,当OSD数量固定时,减少了相关客户端的数据速率。
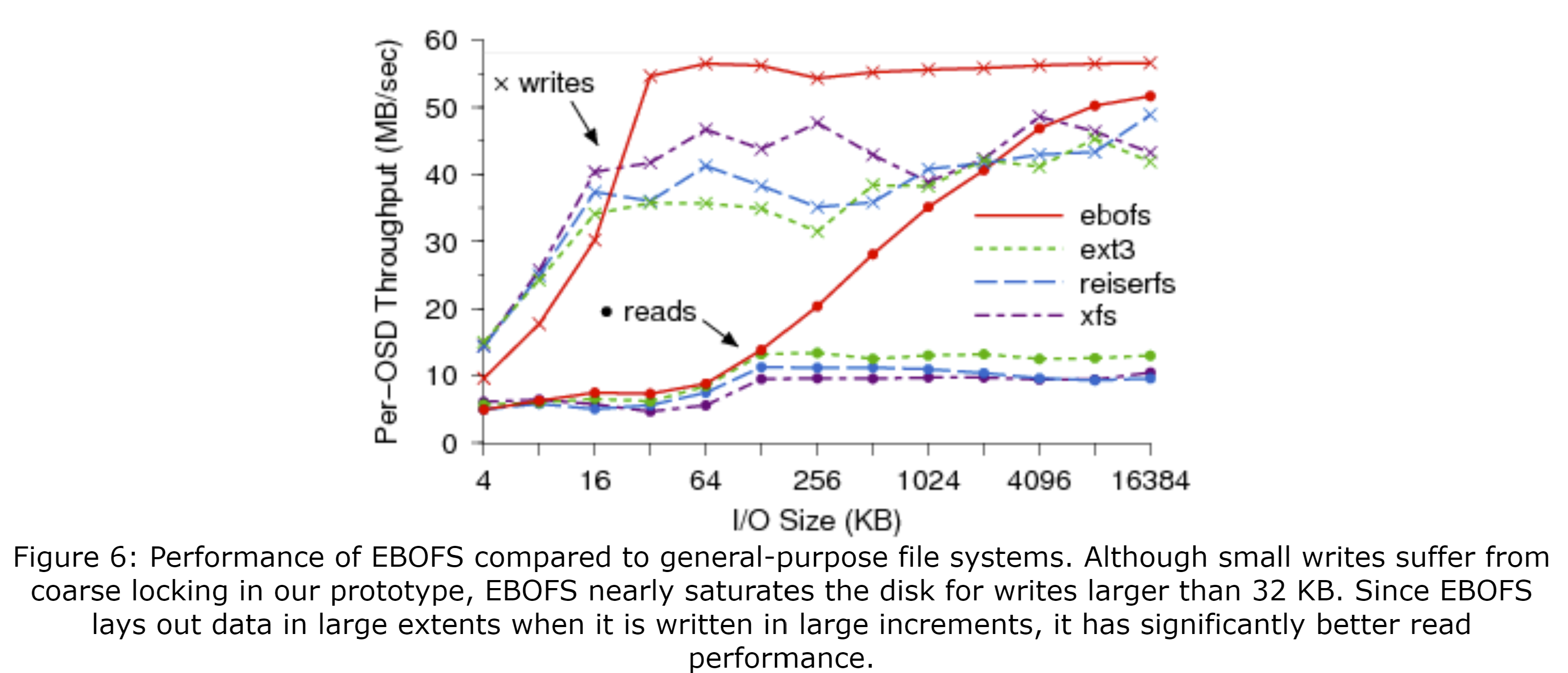
图6比较了EBOFS与通用文件系统(ext3、ReiserFS、XFS)在处理Ceph的负载时的性能。客户端同步地写入大文件,将其分条为16MB的多个对象,并随后读回数据。尽管少量的读取和写入的性能受EBOFS粗粒度的线程和锁的影响很大,但是当写入大小超过32KB时,EBOFS几乎可以使可用的磁盘带宽饱和,且其读取性能比其他文件系统有明显的优势,因为数据被安排到与其大小匹配的磁盘区间上,即使数据很大也是如此。性能通过一个新的文件系统测量.使用早期的EBOFS的实验表明,其产生的碎片比ext3少很多,但是我们还没在用了很久的文件系统上测量过当前实现的情况。无论如何,我们预期用了很久以后,EBOFS的性能也不会比其它的差。
6.1.2 写入延迟
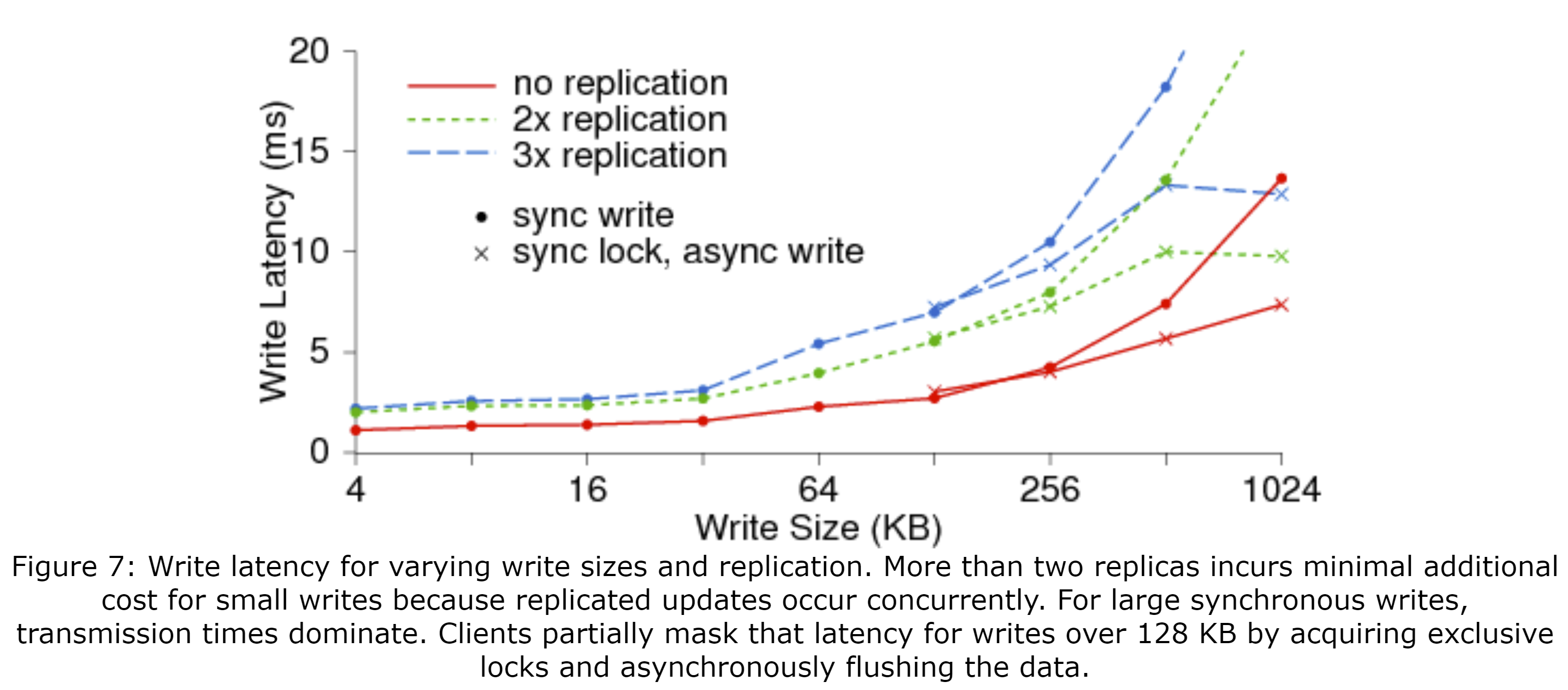
图7展示了单次同步写入不同大小的数据(x轴)和副本数时的延迟(y轴)。因为主OSD同时将更新传输给所有备OSD,对于少量的写入来说,超过两个的副本所带来的额外开销很小。对于大量的写入,传输的开销占了大部分的延迟;单副本1MB的写入(没在图中给出)花了13ms,而三副本的时间长了2.5倍(33ms)。Ceph的客户端在写入超过128KB的数据时通过请求排他锁和异步地将数据冲刷到磁盘上,掩盖了部分的延迟。或者,共享写入的应用程序可以选择使用O_LAZY。由于这样会放松一致性,客户端可以缓冲少量的写入并仅提交大量的写入,异步地写入到OSD中;应用程序能看到的延迟仅为因客户端填满了其缓存而等待数据冲刷到磁盘时的延迟。
6.1.3 数据分布与可伸缩性
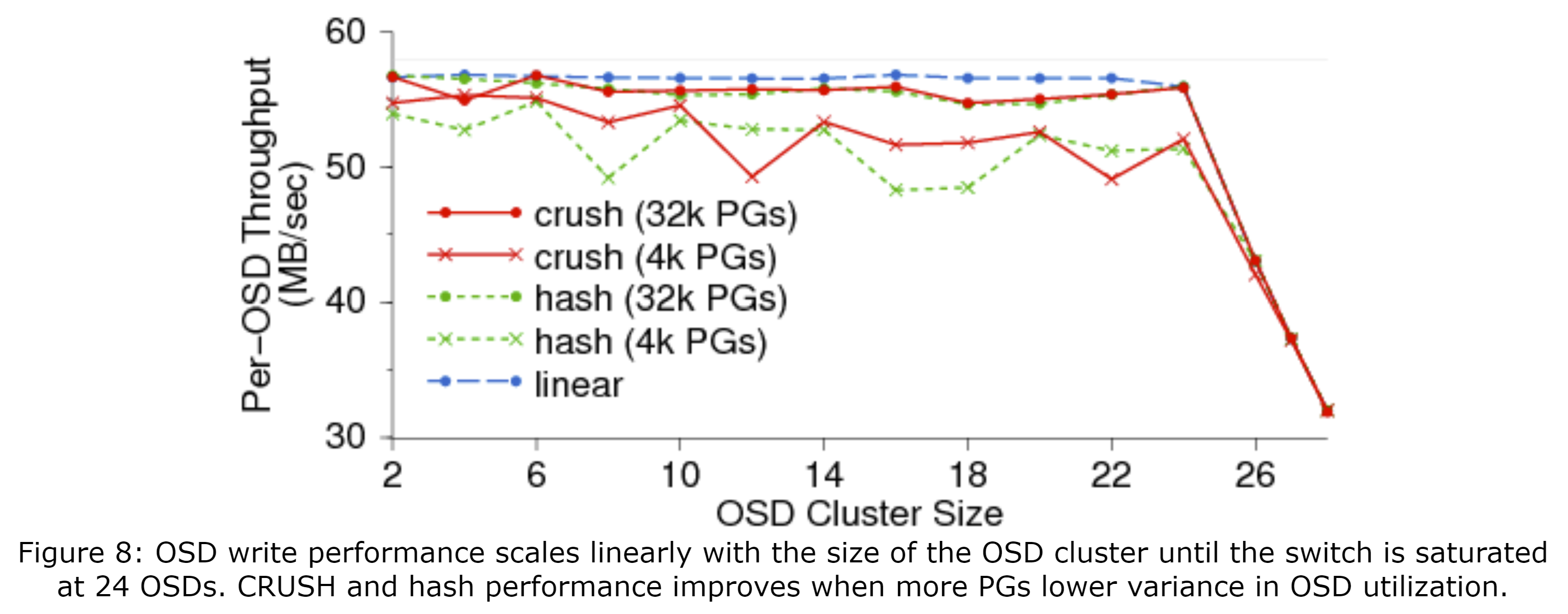
Ceph的数据性能随OSD的数量近似线性地增长。CRUSH伪随机地分布数据,这样OSD的利用率可以通过二项分布或正态分布精确地建模——这是通过完全随机过程的期望得到的[29]。使用率的差异会随着组数量的增加而减少:对于每个OSD上有100个PG的情况,标准差为10%;对于1000个PG的情况,其标准差为3%。图8展示了使用CRUSH、简单哈希函数的集群中每个OSD的吞吐量随集群伸缩的变化,其线性的分条策略将数据分布在可用的OSD上的4096或32768个PG中。线性分条可以很好地平衡负载以增加吞吐量,这给对比提供了benchmark,但与简单的哈希函数一样,它不能处理设备故障或其他的OSD集群更改。因为通过CRUSH或哈希函数的数据放置是随机的,PG数量更少时吞吐量更低:更大的OSD利用率差异在多客户端相互纠缠的情况下导致请求队列长度各异。因为设备可能有很小的概率过载或过度使用,这回拖慢性能,因此CRUSH可以通过卸载集群映射中标记的特定的OSD来修正这种情况。不想哈希和线性的策略,CRUSH还能在集群扩展时减少数据迁移,同时维护数据均衡分布。CRUSH计算复杂度是$O( \log n )$(对于由n个OSD组成的集群来说),在集群增长到有数百或数千个OSD时,也只需要几十毫秒。
6.2 元数据性能
Ceph的MDS集群提供了有极好的可伸缩性的增强POSIX语义。我们通过没有任何数据I/O的部分负载来测量性能;在这些实验中,OSD仅存储元数据。
6.2.1 元数据更新延迟
我们首先考虑元数据更新相关的延迟(例如mknod或mkdir)。单个客户端创建一系列的文件和目录,MDS为了安全起见,必须同步地将其记录到OSD集群的日志中。我们考虑有一个无磁盘的MDS和一个有本地磁盘的OSD,该MDS的所有元数据存储在共享的OSD集群中,而该OSD为其日志的主OSD。**图9(a)**展示了两种情况下在不同的元数据副本数(x轴)(0表示没有日志)时与元数据更新相关的延迟(y轴)。日志条目首先会被写入主OSD中,然后被被分到所有额外的OSD中。对于由本地磁盘的情况,MDS到(本地的)主OSD的第一跳花费的时间最少,而两副本的延迟达到了最初的两倍,并近似与无磁盘模型中一份副本的情况。在两种情况下,超过两副本后额外的延迟很少,因为副本更新是并行的。
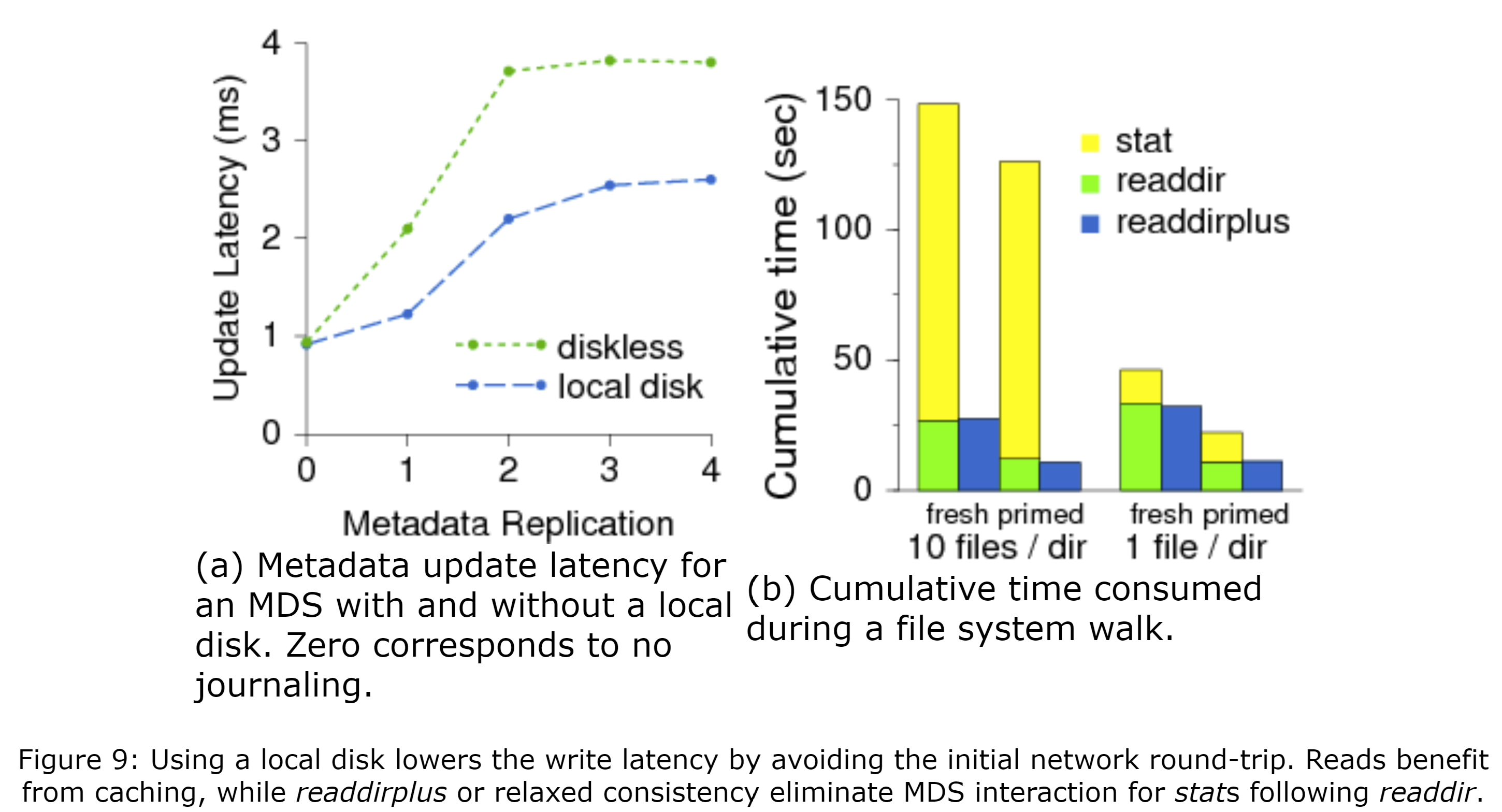
6.2.2 元数据读取延迟
元数据读取(如readdir、stat、open)的行为更加复杂。**图9(b)**展示了客户端对10000个嵌套的目录通过readdir遍历每个目录并对每个文件使用stat时的总时间(y轴)。MDS的热缓存减少了readdior的次数。后续的stat不受影响,因为inode的内容嵌入到了目录中,使仅需一次OSD访问就可以将完整的目录内容拉取到MDS的缓存中。通常,在更大的目录中,stat的总次数会占大部分延迟。后续的MDS交互可通过使用readdirplus来消除,其显式地将stat和readdir的结果捆绑到一次操作中;也可以通过通过放松POSIX请求来使紧跟在readdir后的stat可以从客户端的缓存中获取(默认情况)。
6.2.3 元数据伸缩
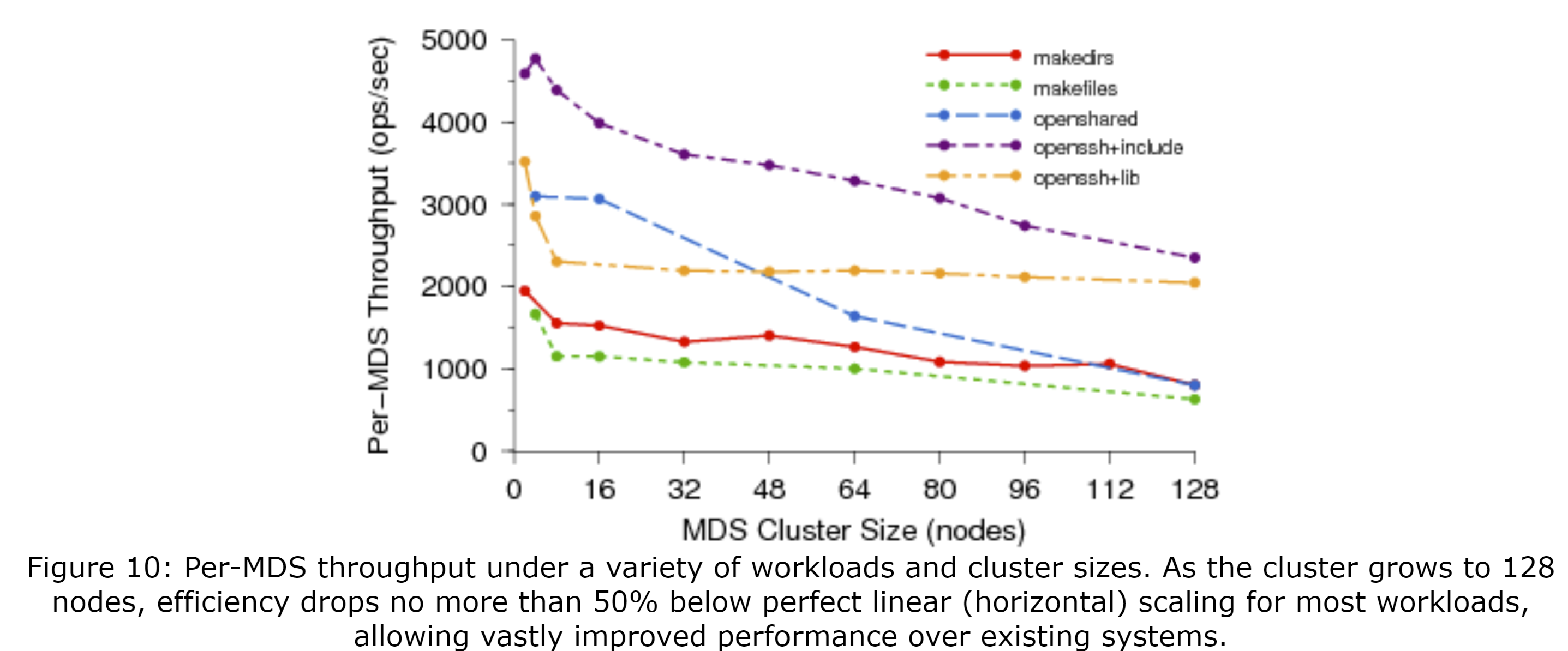
我们使用Lawrence Livermore National Laboratory(LLNL)的alc Linux集群中由430个节点组成的一个分区来评估元数据的可伸缩性。图10展示了每台MDS的吞吐量(y轴)作为MDS集群大小(x轴)的函数,其中水平线表示完全线性伸缩。在makedirs负载中,每个客户端差UN构建一个4层嵌套的目录树,每个目录中有10个文件和1个子目录。在较小的集群中,每台MDS的吞吐量为2000ops/sec, 随着集群扩展到128个MDS时每个MDS的吞吐量大概为1000ops/sec(每台效率下降了50%,总吞吐量为100000ops/sec)。在makefiles的负载中,每个客户端在同一个目录下创建数千个文件。当检测到大量的写入时,Ceph会哈希化共享目录并放松目录的修改时间的连贯性,以将负载分摊到所有MDS节点上。openshared的负载演示了每个客户端反复打开关闭10个共享文件的共享读取。在openssh负载中,每个客户端会在私有目录中重放获取到的一次编译过程中对文件系统的跟踪。一种情况下使用共享的/lib目录,而另一种情况使用/usr/include,第二种情况使用的目录会被大量读取。openshared和openssh+include的负载的共享读取量是最大的,其伸缩表现最差,我们认为这是因客户端对备OSD的选择较差而导致的。openssh+lib比简单的分别makedir的伸缩性更好,因为其有相对少的元数据修改和相对少的共享。尽管我们认为,对于更大的MDS集群来说,在消息传递层的网络和线程的争用会进一步降低性能,但是我们访问大型集群的时间有限,无法进行详细的调查。
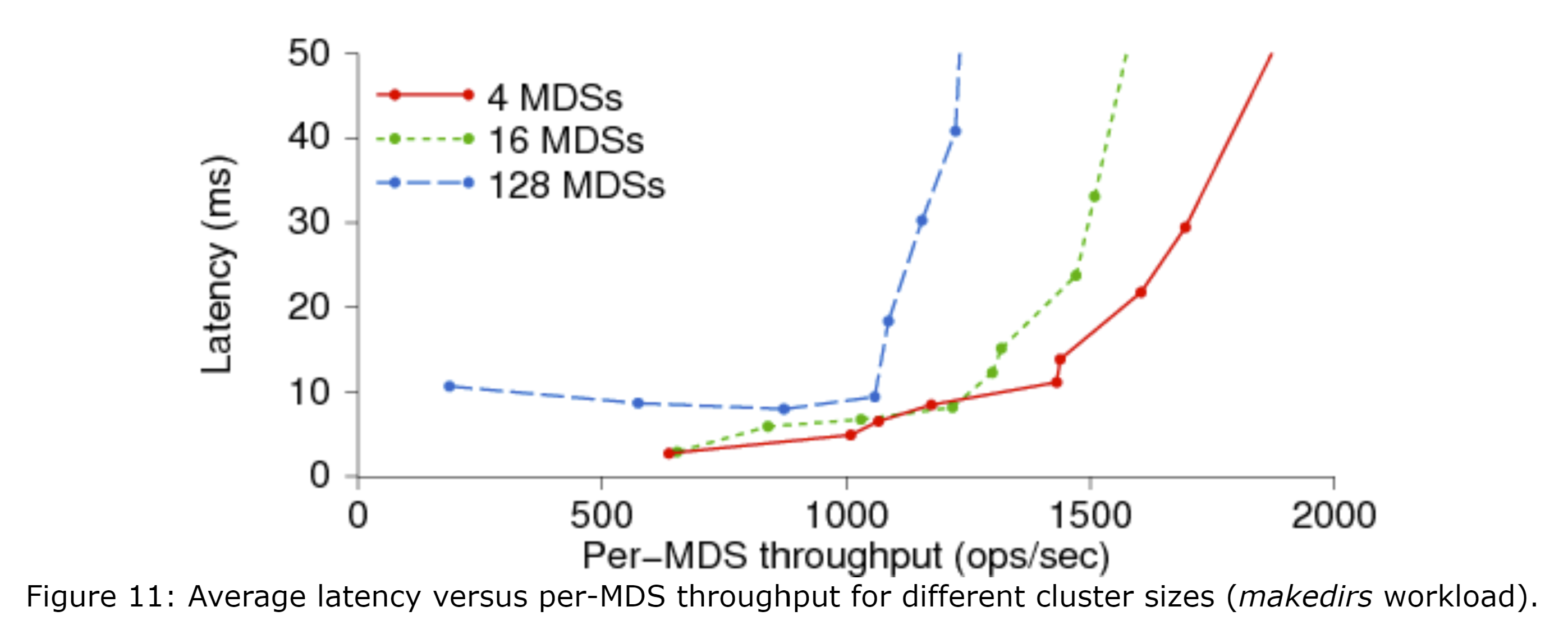
图11展示了分别在4、16、64个节点组成的MDS集群中的makedir负载下,延迟(y轴)和每台MDS吞吐量(x轴)的关系图。较大的集群的负载分布不完美,导致平均每台MDS的吞吐量更低(当然,其总吞吐量更高)且延迟稍高。
尽管这不是完美的线型伸缩,但是128个运行着我们的原型系统的MDS节点组成的集群还是能够提供超过每秒25万次的元数据操作(128台节点的每台节点2000ops/sec)。因为元数据的事务与数据I/O独立,且元数据大小与文件大小无关,所以该性能可能在数百PB或更大的存储中也是如此,这取决于平均文件大小。例如,科学计算应用程序在LLNL的Bluegene/L上的检查点创建可能使用了64000个双处理器的结点,每个节点在相同的目录下写入一个独立的文件(就像makefile的负载那样)。当前的存储系统的元数据操作在6000ops/sec时达到峰值,且完成每个检查点的创建需要花几分钟的时间,而Ceph的MDS集群可以在2秒内完成。如果每个文件仅为10MB(按照HPC的标准来说非常小)且OSD能支撑50MB/sec,这样的集群在使25000台OSD(与50000分副本)饱和的情况下能够以1.25TB/sec的速率写入。250GB的OSD能够构建出超过6PB的系统。更重要的是,Ceph的动态元数据分布让(任何大小的)MDS集群基于当前的负载重新分配资源,即使之前所有客户端都访问被分配到一台MDS上的元数据时也可以,这让Ceph的策略比任何静态分区策略都更具有通用性和适应性。
7. 开发经历
我们惊喜地发现,用分布函数来替代文件分配元数据大大简化了我们的设计。尽管这对函数本身的需求更高,但是一旦我们意识到我们的需求是什么,CRUSH就能够体提供必要的可伸缩性、灵活性、和可靠性。这极大地简化了我们的元数据负载,同时为客户端和OSD提供了与数据分布相关的完整、独立的信息。后者能够让我们把数据复制、迁移、故障检测、和恢复的责任委托给OSD,将这些机制分摊开来可以有效地利用整体的CPU和内存。RADOS为一些列能用在我们OSD模型中的进一步的增强打开了一扇大门,例如位错误检测(如GFS中的[7])和基于负载的动态数据复制(类似AutoRAID[34])。
尽管使用现有的内和文件系统作为本地对象存储很诱人(正如许多其他的系统做的那样[4, 7, 9]),但是我们很早就认识到了,为对象负载量身定制的文件系统能够提供更好的性能[27]。我们没有预料到的是现有的文件系统与我们需求的差异,这在开发RADOS的副本和可靠性机制时变得非常明显。运行在空户空间中的EBOFS的开发速度惊人的快,其提供了非常让人满意的性能并给出了完全符合我们需求的接口。
开发Ceph中我们学到的最重要的知识之一是,MDS负载均衡器对整个系统的可伸缩性的重要性,和选择在什么时候将哪些元数据迁移到哪儿的复杂性。虽然原侧上我们的设计和目标看起来相当简单,但实际上将不断增长的负载分布到超过100个MDS上还有很多额外的细节。最值得注意的是,MDS的性能受很多方面性能的限制,包括CPU、内存(即缓存效率)、网络与I/O的限制,在任一时间性能都可能受任一方面的性能限制。另外,定量地在总吞吐量和公平性之间做出平衡是很难的;在一些情况下,不均衡的元数据分布也可以提高整体吞吐量[30]。
客户端接口的实现带来了比预期更大的挑战。尽管使用FUSE的方式通过避免涉及到内核极大地简化了实现,但是这样也引入了一系列其自己的特性。DIRECT_IO绕过了内核的页缓存,但是不支持mmap,这迫使我们采用修改FUSE以使空白的页失效的解决方案。FUSE坚持执行其自己的安全性检查,这导致即使是简单的应用程序也会大量调用getattr(stat)。最后,内核和用户空间之间的基于页的I/O限制了整体I/O速率。尽管直接链接到客户端避免了FUSE的问题,用户空间过量的系统调用又引入了一系列新问题(其中大部分问题我们还没有完全研究),是客户端必可避免地需要有内核中的模块。
8. 相关工作
高性能可伸缩的文件系统一直以来都是HPC社区的目标之一,HPC往往会给文件系统带来沉重的负载[18, 27]。尽管许多文件系统试图满足这一需求,但是它们都没有提供与Ceph等级相同的可伸缩性。像OceanStore[11]和Farsite[1]这样的大规模系统是为提供PB级的高可靠存储、并使数千个客户端能同时访问不同的数千个文件设计的,但是由于其子系统的瓶颈(如名称查找),它们无法在上万个协作的客户端访问少量文件时提供较高的性能。相反,像Vesta[6]、Galley[17]、PVFS[12]、和Swift[5]这样的并行文件与存储系统为跨多个磁盘分条的数据提供了广泛的支持,但是缺少对可伸缩的元数据访问或高可用的鲁棒性数据分布提供健壮的支持。例如,Vesta允许应用程序将数据放在磁盘上,且允许每个磁盘独立访问文件数据而不需要参考共享的元数据。然而,像其他的并行文件系统一样,Vesta没有提供对元数据查找的可伸缩的支持。因此,这些文件系统在访问大量小文件或需要很多元数据操作时,往往性能很差。它们通常还会遇到块分配的问题:块或中心化分配,或通过基于锁的机制分配,这使它们在面对来组数千个客户端到数千个磁盘的写请求时,无法很好地伸缩。GPFS[24]和StorageTank[16]将元数据管理和数据管理部分解耦,但是它们受基于其使用的基于块的磁盘和元数据分布结构限制。
像LegionFS[33]这样的基于网格的文件系统,被设计用于广域访问,且没有为高性能的本地文件系统优化。类似地,GFS[7]是为非常大的文件和有大量的读取和文件追加的的负载优化。像Sorrento[26]一样,其目标是不使用POSIX语义的很窄的一类应用程序。
最近,许多文件系统和平台(包括Federated Array of Bricks(FAB)[23]、pNFS[9])都是围绕网络附加存储[8]设计的。Lustre[4]、the Panasas File System[32]、zFS[21]、Sorrento、和Kybos,都基于一种基于对象的存储范式[3],且最接近Ceph。然而,这些系统都没有将Ceph提供的可伸缩和可适应的元数据管理及可靠性与容错合并在一起。特别是Lustre和Panasas,它们没有将责任委托给OSD,这限制了它们实现有效的分布式元数据管理,因此限制了它们的可伸缩性和性能。此外,除了使用了一致性哈希[10]的Sorrento,所有的这些系统都使用显式的映射来指定对象存储在哪儿,限制了在新存储部署时的重均衡支持。这会导致负载不对称与资源利用率低,而Sorrento的哈希化的分布缺少CRUSH中对高效数据迁移、设备权重、和故障域的支持。
9. 展望
Ceph的一些核心元素目前还没有被实现,包括MDS故障恢复和一些POSIX调用。两种安全性相关的架构和协议的变体还在考虑中,目前都没有实现[13, 19]。我们还计划调研通过客户端回调进行元数据的命名空间到inode的转换的实用性。对于文件系统的静态区域,这可以在为了去读打开文件时不需要与MDS交互。一些其他的MDS增强还在计划中,包括对目录结构的任意子树创建快照的能力[28]。
尽管当一个目录或文件出现瞬时的大量访问时,Ceph可以动态地为元数据做副本,但目前还没为文件数据实现这种机制。我们计划让OSD能够基于负载动态地为单个对象调整副本等级,并将读取流量分摊到同一PG的多个OSD中。这会让少量数据有可伸缩的访问能力,并使用类似于D-SPTF[15]的机制为OSD提供细粒度的负载均衡。
最后,我们正在开发一种服务质量体系,以结合基于分类的流量优先级和基于OSD管理的预留的带宽和延迟保证。除了为对QoS有需求的应用程序提供支持外,这还会帮助均衡RADOS的副本与一般负载下的恢复操作。计划中还有很多对EBOFS的增强,包括改进的分配逻辑、数据清洗、和能提高数据安全性的校验和或其他位错误检测机制。
10. 结论
Ceph通过独有的设计,解决了存储系统的三个重要挑战:可伸缩性、性能、和可靠性。通过去除几乎所有现有系统中有的像分配列表之类的设计,我们最大限度地将数据与元数据管理分离,让二者可以独立伸缩。这种分离依赖于CRUSH,CRUSh是一个生成伪随机分布的数据分布函数,其让客户端计算对象的位置而不是查找对象的位置。CRUSH强制数据的副本在故障域间分布以提高数据安全性,同时有效地应对了大型存储集群本身的动态特性,如其设备故障、扩展、和集群重组是常态。
RADOS利用了智能OSD来管理数据副本、故障检测与恢复、下层的磁盘分配、调度、和数据迁移,且不涉及任何中央服务器。虽然对象可以被视为文件并存储在通用的文件系统上,但是EBOFS通过解决Ceph中特定的负载和接口需求,提供了更合适的语义和更好的性能。
最后,Ceph的元数据管理架构解决了高度可伸缩存储中最棘手的问题之一——如何高效地提供一个遵循POSIX的、且性能可以随元数据服务器的数量伸缩的统一的目录层次结构。Ceph的动态子树分区是一种独特的可伸缩的方法,其既有高效率,又提供了适应不同多变的负载的能力。
Ceph基于LGPL协议,可在https://ceph.sourceforge.net/中访问。
致谢
这项工作是在美国能源部的支持下,由加州大学劳伦斯利弗莫尔国家实验室根据合同W-7405-Eng-48进行的。这项研究的部分资金由Lawrence Livermore、Los Alamos、和Sandia National Laboratories提供。我们要感谢Bill Loewe、Tyce McLarty、Terry Heidelberg和LLNL的其他所有人,他们向我们讲述了他们的存储试验和困难,并帮我们取得了两天的alc专用访问时间。我们还要感谢IBM提供的32节点OSD集群来做性能测试,以及美国国家科学基金会(National Science Foundation)为交换机升级买单。我们的领导Chandu Thekkath、匿名的审稿人和Theodore Wong都提供了宝贵的反馈,我们也要感谢存储系统研究中心的学生、教师和赞助者的工作与支持。
参考文献
[1] A. Adya, W. J. Bolosky, M. Castro, R. Chaiken, G. Cermak, J. R. Douceur, J. Howell, J. R. Lorch, M. Theimer, and R. Wattenhofer. FARSITE: Federated, available, and reliable storage for an incompletely trusted environment. In Proceedings of the 5th Symposium on Operating Systems Design and Implementation (OSDI), Boston, MA, Dec. 2002. USENIX.
[2] P. A. Alsberg and J. D. Day. A principle for resilient sharing of distributed resources. In Proceedings of the 2nd International Conference on Software Engineering, pages 562-570. IEEE Computer Society Press, 1976.
[3] A. Azagury, V. Dreizin, M. Factor, E. Henis, D. Naor, N. Rinetzky, O. Rodeh, J. Satran, A. Tavory, and L. Yerushalmi. Towards an object store. In Proceedings of the 20th IEEE / 11th NASA Goddard Conference on Mass Storage Systems and Technologies, pages 165-176, Apr. 2003.
[4] P. J. Braam. The Lustre storage architecture. https://www.lustre.org/documentation.html, Cluster File Systems, Inc., Aug. 2004.
[5] L.-F. Cabrera and D. D. E. Long. Swift: Using distributed disk striping to provide high I/O data rates. Computing Systems, 4(4):405-436, 1991.
[6] P. F. Corbett and D. G. Feitelson. The Vesta parallel file system. ACM Transactions on Computer Systems, 14(3):225-264, 1996.
[7] S. Ghemawat, H. Gobioff, and S.-T. Leung. The Google file system. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP ‘03), Bolton Landing, NY, Oct. 2003. ACM.
[8] G. A. Gibson, D. F. Nagle, K. Amiri, J. Butler, F. W. Chang, H. Gobioff, C. Hardin, E. Riedel, D. Rochberg, and J. Zelenka. A cost-effective, high-bandwidth storage architecture. In Proceedings of the 8th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 92-103, San Jose, CA, Oct. 1998.
[9] D. Hildebrand and P. Honeyman. Exporting storage systems in a scalable manner with pNFS. Technical Report CITI-05-1, CITI, University of Michigan, Feb. 2005.
[10] D. Karger, E. Lehman, T. Leighton, M. Levine, D. Lewin, and R. Panigrahy. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web. In ACM Symposium on Theory of Computing, pages 654-663, May 1997.
[11] J. Kubiatowicz, D. Bindel, Y. Chen, P. Eaton, D. Geels, R. Gummadi, S. Rhea, H. Weatherspoon, W. Weimer, C. Wells, and B. Zhao. OceanStore: An architecture for global-scale persistent storage. In Proceedings of the 9th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Cambridge, MA, Nov. 2000. ACM.
[12] R. Latham, N. Miller, R. Ross, and P. Carns. A next-generation parallel file system for Linux clusters. LinuxWorld, pages 56-59, Jan. 2004.
[13] A. Leung and E. L. Miller. Scalable security for large, high performance storage systems. In Proceedings of the 2006 ACM Workshop on Storage Security and Survivability. ACM, Oct. 2006.
[14] B. Liskov, S. Ghemawat, R. Gruber, P. Johnson, L. Shrira, and M. Williams. Replication in the Harp file system. In Proceedings of the 13th ACM Symposium on Operating Systems Principles (SOSP ‘91), pages 226-238. ACM, 1991.
[15] C. R. Lumb, G. R. Ganger, and R. Golding. D-SPTF: Decentralized request distribution in brick-based storage systems. In Proceedings of the 11th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 37-47, Boston, MA, 2004.
[16] J. Menon, D. A. Pease, R. Rees, L. Duyanovich, and B. Hillsberg. IBM Storage Tank-a heterogeneous scalable SAN file system. IBM Systems Journal, 42(2):250-267, 2003.
[17] N. Nieuwejaar and D. Kotz. The Galley parallel file system. In Proceedings of 10th ACM International Conference on Supercomputing, pages 374-381, Philadelphia, PA, 1996. ACM Press.
[18] N. Nieuwejaar, D. Kotz, A. Purakayastha, C. S. Ellis, and M. Best. File-access characteristics of parallel scientific workloads. IEEE Transactions on Parallel and Distributed Systems, 7(10):1075-1089, Oct. 1996.
[19] C. A. Olson and E. L. Miller. Secure capabilities for a petabyte-scale object-based distributed file system. In Proceedings of the 2005 ACM Workshop on Storage Security and Survivability, Fairfax, VA, Nov. 2005.
[20] B. Pawlowski, C. Juszczak, P. Staubach, C. Smith, D. Lebel, and D. Hitz. NFS version 3: Design and implementation. In Proceedings of the Summer 1994 USENIX Technical Conference, pages 137-151, 1994.
[21] O. Rodeh and A. Teperman. zFS-a scalable distributed file system using object disks. In Proceedings of the 20th IEEE / 11th NASA Goddard Conference on Mass Storage Systems and Technologies, pages 207-218, Apr. 2003.
[22] D. Roselli, J. Lorch, and T. Anderson. A comparison of file system workloads. In Proceedings of the 2000 USENIX Annual Technical Conference, pages 41-54, San Diego, CA, June 2000. USENIX Association.
[23] Y. Saito, S. Frølund, A. Veitch, A. Merchant, and S. Spence. FAB: Building distributed enterprise disk arrays from commodity components. In Proceedings of the 11th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 48-58, 2004.
[24] F. Schmuck and R. Haskin. GPFS: A shared-disk file system for large computing clusters. In Proceedings of the 2002 Conference on File and Storage Technologies (FAST), pages 231-244. USENIX, Jan. 2002.
[25] M. Szeredi. File System in User Space. https://fuse.sourceforge.net, 2006.
[26] H. Tang, A. Gulbeden, J. Zhou, W. Strathearn, T. Yang, and L. Chu. A self-organizing storage cluster for parallel data-intensive applications. In Proceedings of the 2004 ACM/IEEE Conference on Supercomputing (SC ‘04), Pittsburgh, PA, Nov. 2004.
[27] F. Wang, Q. Xin, B. Hong, S. A. Brandt, E. L. Miller, D. D. E. Long, and T. T. McLarty. File system workload analysis for large scale scientific computing applications. In Proceedings of the 21st IEEE / 12th NASA Goddard Conference on Mass Storage Systems and Technologies, pages 139-152, College Park, MD, Apr. 2004.
[28] S. A. Weil. Scalable archival data and metadata management in object-based file systems. Technical Report SSRC-04-01, University of California, Santa Cruz, May 2004.
[29] S. A. Weil, S. A. Brandt, E. L. Miller, and C. Maltzahn. CRUSH: Controlled, scalable, decentralized placement of replicated data. In Proceedings of the 2006 ACM/IEEE Conference on Supercomputing (SC ‘06), Tampa, FL, Nov. 2006. ACM.
[30] S. A. Weil, K. T. Pollack, S. A. Brandt, and E. L. Miller. Dynamic metadata management for petabyte-scale file systems. In Proceedings of the 2004 ACM/IEEE Conference on Supercomputing (SC ‘04). ACM, Nov. 2004.
[31] B. Welch. POSIX IO extensions for HPC. In Proceedings of the 4th USENIX Conference on File and Storage Technologies (FAST), Dec. 2005.
[32] B. Welch and G. Gibson. Managing scalability in object storage systems for HPC Linux clusters. In Proceedings of the 21st IEEE / 12th NASA Goddard Conference on Mass Storage Systems and Technologies, pages 433-445, Apr. 2004.
[33] B. S. White, M. Walker, M. Humphrey, and A. S. Grimshaw. LegionFS: A secure and scalable file system supporting cross-domain high-performance applications. In Proceedings of the 2001 ACM/IEEE Conference on Supercomputing (SC ‘01), Denver, CO, 2001.
[34] J. Wilkes, R. Golding, C. Staelin, and T. Sullivan. The HP AutoRAID hierarchical storage system. In Proceedings of the 15th ACM Symposium on Operating Systems Principles (SOSP ‘95), pages 96-108, Copper Mountain, CO, 1995. ACM Press.
[35] T. M. Wong, R. A. Golding, J. S. Glider, E. Borowsky, R. A. Becker-Szendy, C. Fleiner, D. R. Kenchammana-Hosekote, and O. A. Zaki. Kybos: self-management for distributed brick-base storage. Research Report RJ 10356, IBM Almaden Research Center, Aug. 2005.
[36] J. C. Wu and S. A. Brandt. The design and implementation of AQuA: an adaptive quality of service aware object-based storage device. In Proceedings of the 23rd IEEE / 14th NASA Goddard Conference on Mass Storage Systems and Technologies, pages 209-218, College Park, MD, May 2006.
[37] Q. Xin, E. L. Miller, and T. J. E. Schwarz. Evaluation of distributed recovery in large-scale storage systems. In Proceedings of the 13th IEEE International Symposium on High Performance Distributed Computing (HPDC), pages 172-181, Honolulu, HI, June 2004.